


Perplexity AI за три года прошла путь от стартапа до компании с оценкой $20 миллиардов, привлекла $1.2 миллиарда инвестиций и стала одним из главных конкурентов Google в сегменте AI-поиска. Платформа обрабатывает более 100 миллионов запросов в неделю для 15+ миллионов пользователей, используя гибридную архитектуру на базе Vespa.ai и доступ к топовым языковым моделям. В этом материале — детальный разбор технологии, практические кейсы применения, актуальные тарифы 2025 года и честный анализ рисков для тех, кто хочет понять, стоит ли инструмент внимания и денег.
[Источник]
Что такое Perplexity AI и зачем она нужна
Perplexity AI называет себя «ответ-движком» — это сервис, который работает иначе, чем привычный Google. Вместо списка синих ссылок вы сразу получаете готовый ответ с цитатами из проверенных источников.
Как это работает? Perplexity соединяет возможности генеративных языковых моделей с онлайн-поиском. Вы задаёте вопрос — система находит актуальную информацию в интернете и формирует структурированный ответ со ссылками на источники.
Главная идея компании — сэкономить ваше время. Не нужно открывать десятки вкладок, сравнивать статьи и выуживать факты. Perplexity делает это за вас и выдаёт достоверную информацию в один клик.
Почему такой формат стал популярным? После появления ChatGPT и Bing Chat пользователи поняли: диалоговый интерфейс удобнее традиционной поисковой выдачи. Легче уточнить вопрос в диалоге, чем заново формулировать запрос и снова копаться в результатах.
Кому это полезно:
- Студенты получают готовые конспекты с источниками для рефератов и курсовых
- Специалисты быстро проверяют факты, не тратя время на чтение десятков статей
- Бизнес-аналитики собирают рыночные данные без ручного парсинга сайтов и отчётов
Чтобы понять, почему Perplexity стала одним из лидеров в этой нише, стоит узнать историю компании.
От гаража к единорогу: история и деньги
Perplexity появилась в 2022 году. Компанию основали четыре человека с внушительным бэкграундом — Арвинд Сринивас, Денис Ярац, Джонни Хо и Энди Коновински. Все они работали в OpenAI, Quora и Databricks, то есть знали индустрию изнутри.
За три года стартап прошёл путь от раунда А до раунда D, привлёк $1,2 млрд инвестиций. К сентябрю 2025 года оценка компании достигла $20 млрд — статус единорога давно в прошлом.
Кто поверил в проект? В списке инвесторов — SoftBank Vision Fund 2, NVIDIA, IVP, NEA и фонд Джеффа Безоса. Это не просто деньги, это репутация: когда такие игроки вкладываются, рынок обращает внимание.

[Источник]
Интересный факт: ещё в декабре 2024 года компания закрыла раунд на оценке $9 млрд. За девять месяцев оценка выросла больше чем вдвое — это подтверждает, что модель «ответ-движка» действительно востребована.
Зная, кто стоит за продуктом и какие ресурсы у команды, логично разобраться, как устроена технология внутри.
Как это устроено: движок знаний Perplexity
В основе Perplexity лежит технология RAG — Retrieval-Augmented Generation. Это подход, при котором языковая модель не выдумывает ответ из того, что помнит после обучения, а сначала ищет свежую информацию в реальном времени, а затем формирует текст на основе найденного.
Принцип работы в четыре шага:
- Анализ запроса — система понимает, что именно вы хотите узнать
- Поиск релевантных источников — находит документы в интернете и внутренних базах
- Отбор ключевой информации — выбирает самые важные фрагменты из найденного
- Генерация ответа — составляет связный текст со ссылками на источники
Звучит просто, но за этим стоит серьёзная инфраструктура.
Техническая основа: Vespa.ai
Perplexity построена на платформе Vespa.ai — это движок, который обрабатывает поиск в реальном времени на уровне миллиардов документов. Vespa индексирует страницы из публичного интернета и приватные файлы пользователей, постоянно обновляя индекс.
Масштаб системы:
- Обрабатывает тысячи запросов в секунду
- Время отклика — сотни миллисекунд
- Индексирует миллиарды веб-страниц и пользовательских документов
- Обновляет данные в реальном времени
Для скорости работы Perplexity держит собственный индекс и кэш. Это позволяет не обращаться к внешним API каждый раз, а использовать уже обработанные данные.
Гибридный поиск: не только векторы
Многие думают, что современные AI-системы работают только с векторными embeddings — когда текст превращается в числовые представления. Perplexity использует гибридный подход, комбинируя несколько методов одновременно:
Традиционные методы:
- BM25 — алгоритм, который ранжирует документы по ключевым словам (более продвинутая версия TF-IDF)
- N-gram поиск — находит совпадения последовательностей слов
- PageRank-подобные сигналы — учитывает авторитетность домена
Современные методы:
- Векторные embeddings — семантический поиск по смыслу, а не по точным словам
- Метаданные и фильтрация — время публикации, тип источника, структурированные данные
Vespa объединяет всё это в один запрос. Система использует keyword-поиск, векторное сравнение и структурированные фильтры одновременно, а затем применяет машинное обучение для финального ранжирования результатов.
Почему это важно? Векторы хороши для понимания смысла, но часто упускают точные совпадения. Классический поиск по ключевым словам, наоборот, отлично находит конкретные термины, но не понимает синонимы. Комбинация даёт лучший результат.
Обработка документов
Когда вы загружаете PDF или другой файл, Perplexity не просто скармливает его модели целиком. Система разбивает документ на управляемые блоки — параграфы или секции — и встраивает их в retrieval-слой отдельно.
Это решает проблему контекстного окна: модель может извлечь нужный фрагмент из большого документа, не загружая его полностью. Если у вас PDF на 200 страниц, система найдёт релевантные абзацы на страницах 47 и 134, не обрабатывая всё остальное.
Модели генерации: от чернового ответа до финала
После того как retrieval-слой нашёл релевантные документы, в дело вступают языковые модели.
Sonar — собственная модель Perplexity, создаёт быстрый черновой ответ. Она оптимизирована под скорость и подходит для простых запросов.
GPT-4 Omni и Claude 3 — подключаются для сложных задач, где нужна глубина и точность. Вы можете переключать модели вручную в интерфейсе, выбирая баланс между скоростью и качеством ответа.
Почему это полезно? Быстрый вопрос типа «столица Франции» не требует мощной модели — Sonar справится за секунду. А вот анализ научной статьи или сравнение инвестиционных стратегий лучше отдать Claude или GPT-4.
Для разработчиков: Search API
Если вы хотите встроить Perplexity в свой продукт, есть Search API. Это тот же механизм real-time поиска через REST, но с гибкими настройками:
- Фильтрация по доменам (можно ограничить поиск только научными сайтами или новостными ресурсами)
- Доступ к сырым результатам поиска до генерации ответа
- Контроль над тем, какие модели использовать
Технология на месте, инфраструктура масштабируется. Теперь посмотрим, как всё это превращается в конкретные инструменты для пользователя.

[Источник]
[Источник]
Режимы и инструменты: Search, Deep Research, Copilot, Spaces, Comet
Техническая платформа — это фундамент. Но что именно получает пользователь, открывая Perplexity? Давайте разберём инструменты, которые превращают RAG-архитектуру в работающий продукт.
Quick Search и Pro Search: быстро или глубоко
Quick Search — режим по умолчанию. Подходит для простых вопросов, когда нужен быстрый ответ с источниками. Система находит 5-10 релевантных документов, формирует краткий ответ со ссылками и выдаёт результат за несколько секунд.
Когда этого достаточно? Столица страны, курс валюты, определение термина — всё, что не требует глубокого анализа.
Pro Search — это другой уровень. Здесь подключаются GPT-4 Omni и Claude 3, система проводит многошаговое исследование и показывает процесс рассуждений. Вы видите, как модель разбирает ваш запрос на части, ищет информацию по каждой и синтезирует финальный ответ.
Ключевое отличие — уточняющие вопросы. Pro Search может спросить, что именно вас интересует, прежде чем начать поиск. Это экономит время и повышает точность результата.
Дополнительные возможности Pro Search:
- Code interpreter — выполняет код прямо в интерфейсе для анализа данных и отладки
- Режимы фокусировки — Web, Academic, Finance, Files (можно ограничить поиск только научными источниками или внутренними документами)
- Больше источников — до 20-30 вместо 5-10
Ограничения: бесплатные пользователи получают 5 Pro-поисков каждые 4 часа. Подписчики Pro — 300+ в день.
Deep Research: когда нужен отчёт, а не ответ
Если Pro Search — это продвинутый поиск, то Deep Research — это автоматизированный аналитик. Режим создан для задач, которые у человека заняли бы несколько часов.
[Источник]
Как работает Deep Research:
Вы задаёте сложный вопрос. Система запускает десятки поисков, читает сотни статей, использует iterative reasoning — уточняет план исследования по мере того, как узнаёт больше о теме. Через 2-4 минуты вы получаете структурированный отчёт с разделами, выводами и ссылками на источники.
Под капотом — кастомная версия модели DeepSeek R1 и proprietary framework под названием test-time compute expansion. Это позволяет системе имитировать человеческий процесс исследования: найти информацию → проанализировать → понять, чего не хватает → искать дальше.
Насколько это точно? Perplexity Deep Research набрал 21.1% точности на Humanity’s Last Exam — бенчмарке из 3000+ вопросов по математике, науке, истории и литературе. Это выше, чем у Gemini Thinking и DeepSeek-R1.
Когда использовать:
- Рыночный анализ для бизнес-стратегии
- Обзор литературы для диплома или научной статьи
- Сравнение конкурентов с детальными метриками
- Любая задача, где нужен не ответ, а полноценный документ
Экспорт результата: отчёт можно сохранить как PDF или превратить в Perplexity Page — публичную страницу, которой легко поделиться.
Лимиты: бесплатные пользователи — 5 запросов в день, Pro — 500.
Copilot: диалог вместо угадывания
[Источник]
Часто вы не знаете точно, как сформулировать запрос. Copilot решает эту проблему через диалог.
Вы включаете режим Copilot и вводите общий запрос. Вместо того чтобы сразу искать, система задаёт уточняющие вопросы. Хотите купить наушники? Copilot спросит: бюджет, тип (накладные/вкладыши), для чего (музыка/спорт/работа), важно ли шумоподавление.
После того как вы ответите, модель проводит прицельный поиск с учётом всех ваших требований. Это экономит циклы «запрос → не то → уточнение → новый запрос».
Технически: Copilot работает на GPT-4 и использует multi-turn reasoning — сохраняет контекст диалога, чтобы каждый следующий вопрос учитывал предыдущие ответы.
Примеры задач:
- Планирование путешествий (Copilot уточнит бюджет, интересы, даты)
- Персональные рекомендации (диета, тренировки — система спросит вес, возраст, ограничения)
- Выбор продуктов (техника, софт — уточнит требования и приоритеты)
Лимиты: 5 запросов каждые 4 часа для бесплатных пользователей, 300 в день для Pro.
Spaces: рабочие хабы для проектов
Представьте папку, внутри которой живут все диалоги по одной теме, плюс файлы, плюс настройки для AI. Это Spaces.
Зачем нужны Spaces:
Когда вы работаете над проектом, исследованием или курсовой, информация разбросана: одни Thread’ы здесь, другие там, файлы на диске. Spaces собирают всё в одно место.
Что можно делать:
- Загружать до 50 файлов (PDF, Word, таблицы) — система будет искать информацию одновременно в веб и в ваших документах
- Устанавливать кастомные инструкции — задать тон, формат или контекст, который применится ко всем диалогам в Space
- Выбирать модель — можно закрепить GPT-4 или Claude для всего проекта
- Приглашать до 10 коллабораторов — коллеги смогут создавать Thread’ы, задавать вопросы, делиться находками
Примеры использования:
- Студенты хранят лекции и собирают шпаргалки к экзаменам
- Юристы загружают контракты и получают резюме с выявленными рисками
- Маркетологи создают контент-планы, ссылаясь на внутренние брифы и веб-источники одновременно
Spaces vs Collections: Spaces — это улучшенная версия старых Collections. Главное отличие — теперь можно искать не только в веб, но и в личных файлах, плюс расширенные возможности коллаборации.
Доступ: базовая версия есть у всех, но загрузка файлов и продвинутые функции — только в Pro и Enterprise.
Comet: экспериментальный AI-браузер
Comet — это отдельный браузер от Perplexity, который автоматизирует веб-серфинг и планирует задачи. В 2025 году стал бесплатным.
Идея простая: вы задаёте цель, а браузер сам ищет информацию, открывает нужные страницы, собирает данные. Это эксперимент в сторону более автономного AI, который не просто отвечает на вопросы, но и выполняет действия от вашего имени.
Comet пока что нишевый инструмент, но показывает направление, куда движется компания — AI не как помощник, а как агент.
Набор инструментов понятен. Теперь посмотрим, как начать работу с Perplexity на практике.
Практика: первый запрос за 5 минут
Теория на месте, инструменты разобраны. Пора запустить Perplexity и попробовать на реальной задаче. Вот пошаговый план для новичка.
Регистрация и первая настройка
Откройте perplexity.ai и зарегистрируйтесь через email или Google. Процесс занимает буквально 30 секунд — никаких длинных форм.
Первым делом зайдите в Settings и переключите язык интерфейса на русский, если вам так удобнее. Система поддерживает многоязычность, но поиск по умолчанию работает лучше на английском — учтите это при формулировке сложных запросов.
Навигация: где что находится
Верхняя панель:
- Threads — ваши диалоги (история запросов и ответов)
- Discover — популярные темы и тренды, можно посмотреть, что ищут другие
- Spaces — папки проектов, если вы уже создали рабочие хабы
Строка поиска в центре — здесь начинается всё. Слева от строки — переключатель режимов (Quick/Pro/Deep Research/Copilot), справа — кнопка фокусировки (Web/Academic/YouTube и т.д.).
Как формулировать запрос
Perplexity понимает естественный язык, поэтому пишите так, как задали бы вопрос коллеге. Одно-два предложения, без лишних деталей.
Примеры хороших запросов:
- «Какие языковые модели лучше всего подходят для анализа медицинских данных?»
- «Сравни инвестиционные стратегии Warren Buffett и Ray Dalio»
- «Как настроить CI/CD pipeline для Next.js проекта на Vercel?»
Чего избегать:
- Слишком общие формулировки («расскажи про AI») — лучше уточнить контекст
- Несколько вопросов в одном запросе — разбейте на отдельные
- Поиск по ключевым словам в стиле Google — Perplexity понимает вопросы, не списки слов
Работа с ответом
Система выдаст ответ с цитатами. Каждая цифра в квадратных скобках — это ссылка на источник. Кликните, и откроется оригинальная статья или документ.
Уточнения в том же Thread: не начинайте новый диалог, если нужно углубиться. Задайте follow-up вопрос в той же ветке — контекст сохранится, и модель поймёт, что вы продолжаете предыдущую тему.
Например:
- Первый запрос: «Какие фреймворки используются для RAG?»
- Уточнение: «А какой из них лучше для production?»
- Ещё глубже: «Покажи примеры кода для LangChain»
Лайфхак: переключение моделей и фильтров
Если ответ не устраивает, не переписывайте запрос сразу. Попробуйте другую модель.
Как это сделать: нажмите кнопку «Rewrite» под ответом и выберите другую модель из списка (Sonar → GPT-4 Omni → Claude 3). Каждая модель имеет свои сильные стороны — Sonar быстрая, GPT-4 лучше в рассуждениях, Claude хорош в структурировании текста.
Фильтры источников: слева от строки поиска можно выбрать, где искать. Если нужны только научные статьи — переключитесь на Academic. Ищете видео-туториалы — выберите YouTube. Это резко повышает качество результата для специфичных задач.
Проверка фактов через цитаты
Perplexity не застрахована от ошибок. Если информация критична — всегда проверяйте источники.
Кликните на номер цитаты, откройте оригинал и убедитесь, что система правильно интерпретировала данные. Особенно важно для:
- Финансовых решений
- Медицинских рекомендаций
- Юридических вопросов
- Технических спецификаций
Если источник сомнительный (неизвестный блог, форум, устаревшая статья) — ищите подтверждение из более авторитетных мест.
Первый практический кейс
Давайте разберём реальный сценарий. Допустим, вы выбираете CRM-систему для малого бизнеса.
Шаг 1: Включите Pro Search и введите: «Сравни HubSpot, Pipedrive и Salesforce для команды из 10 человек в b2b-сегменте»
[Источник]
Шаг 2: Perplexity задаст уточняющие вопросы (если Copilot включён): бюджет, нужны ли интеграции, важна ли русификация.
Шаг 3: Получите структурированный ответ с таблицей сравнения, ценами, плюсами и минусами каждой системы.
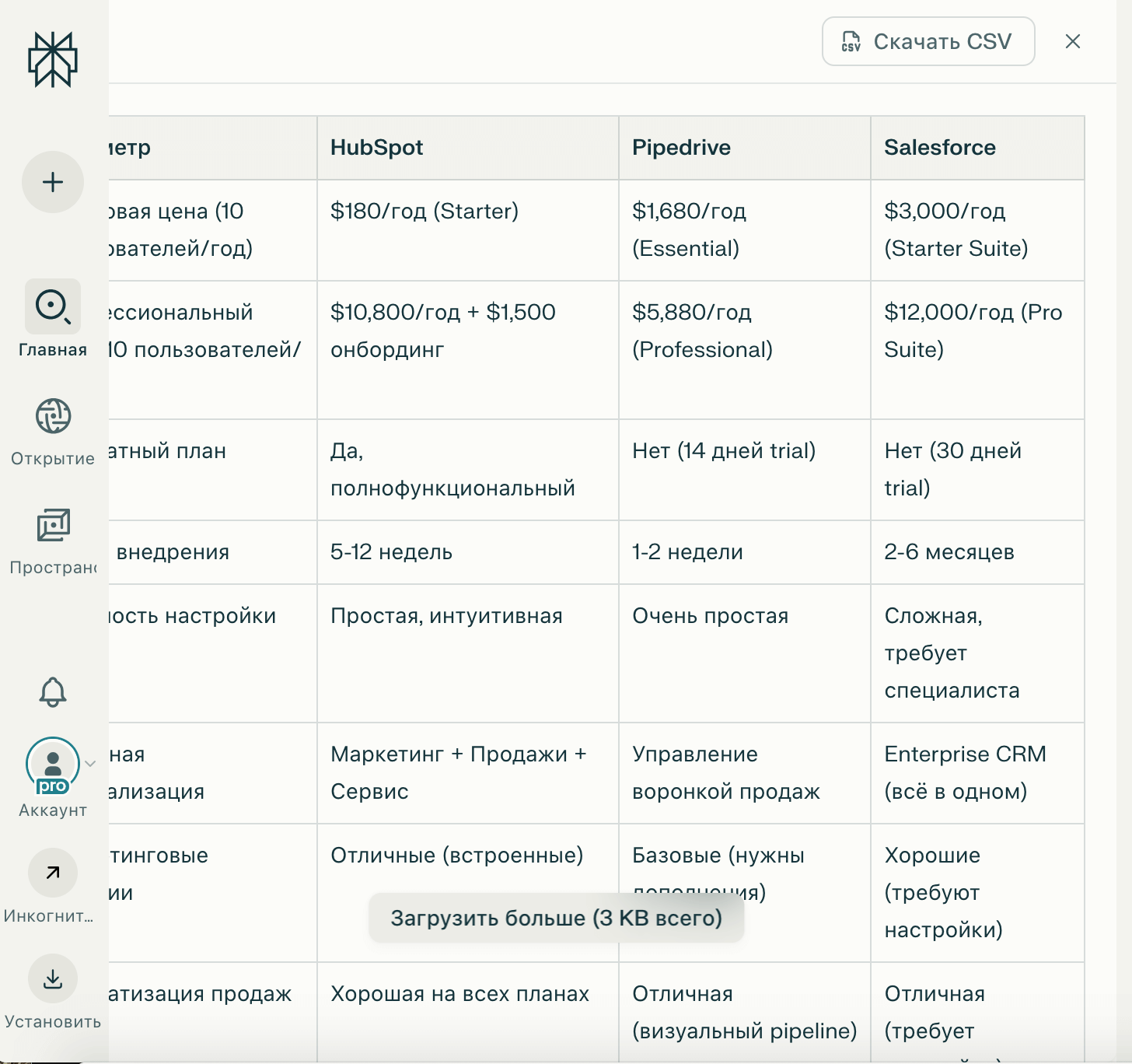
[Источник]
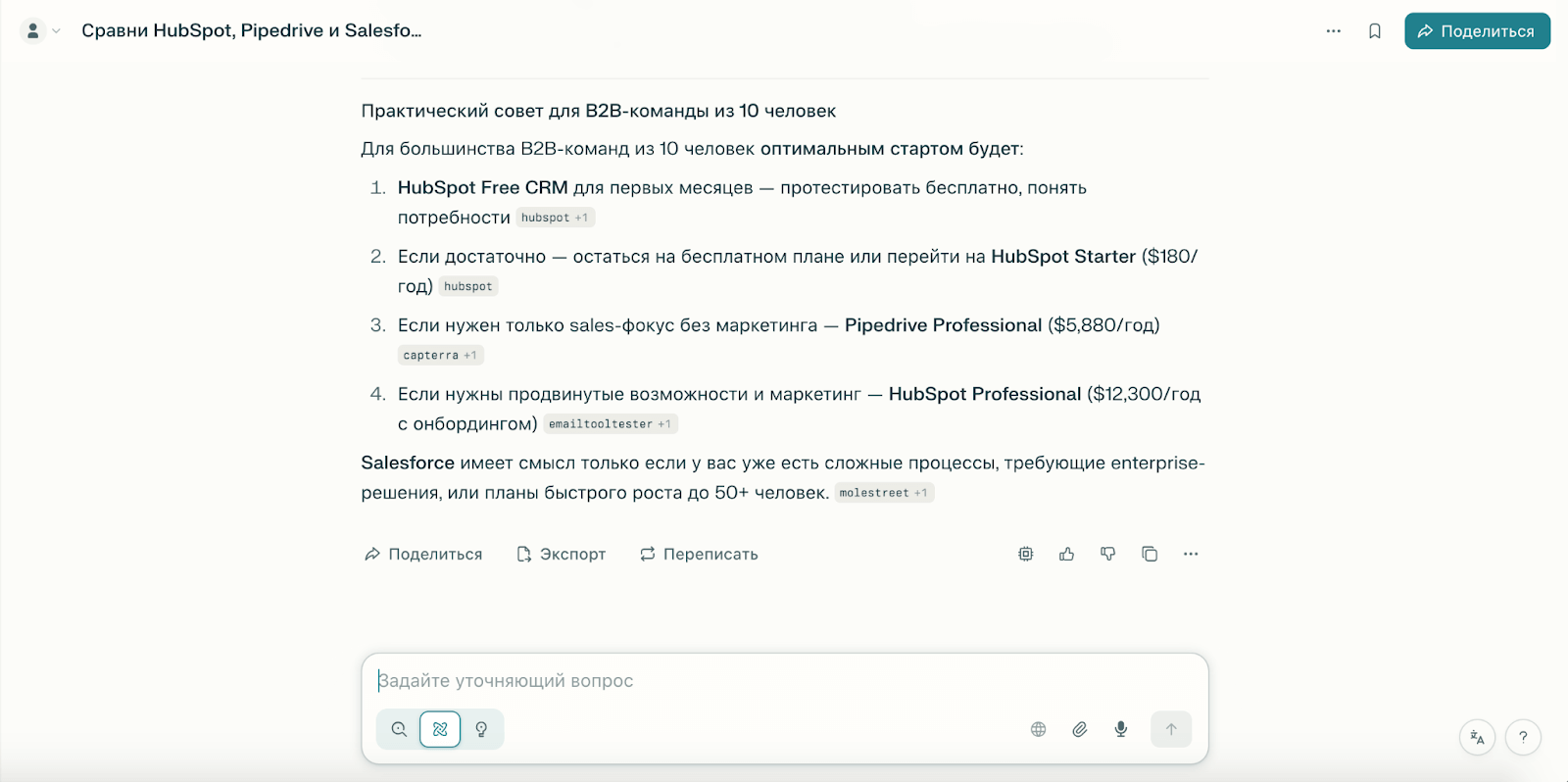
[Источник]
Шаг 4: Уточните детали: «А какие интеграции есть у Pipedrive с email-сервисами?»
[Источник]
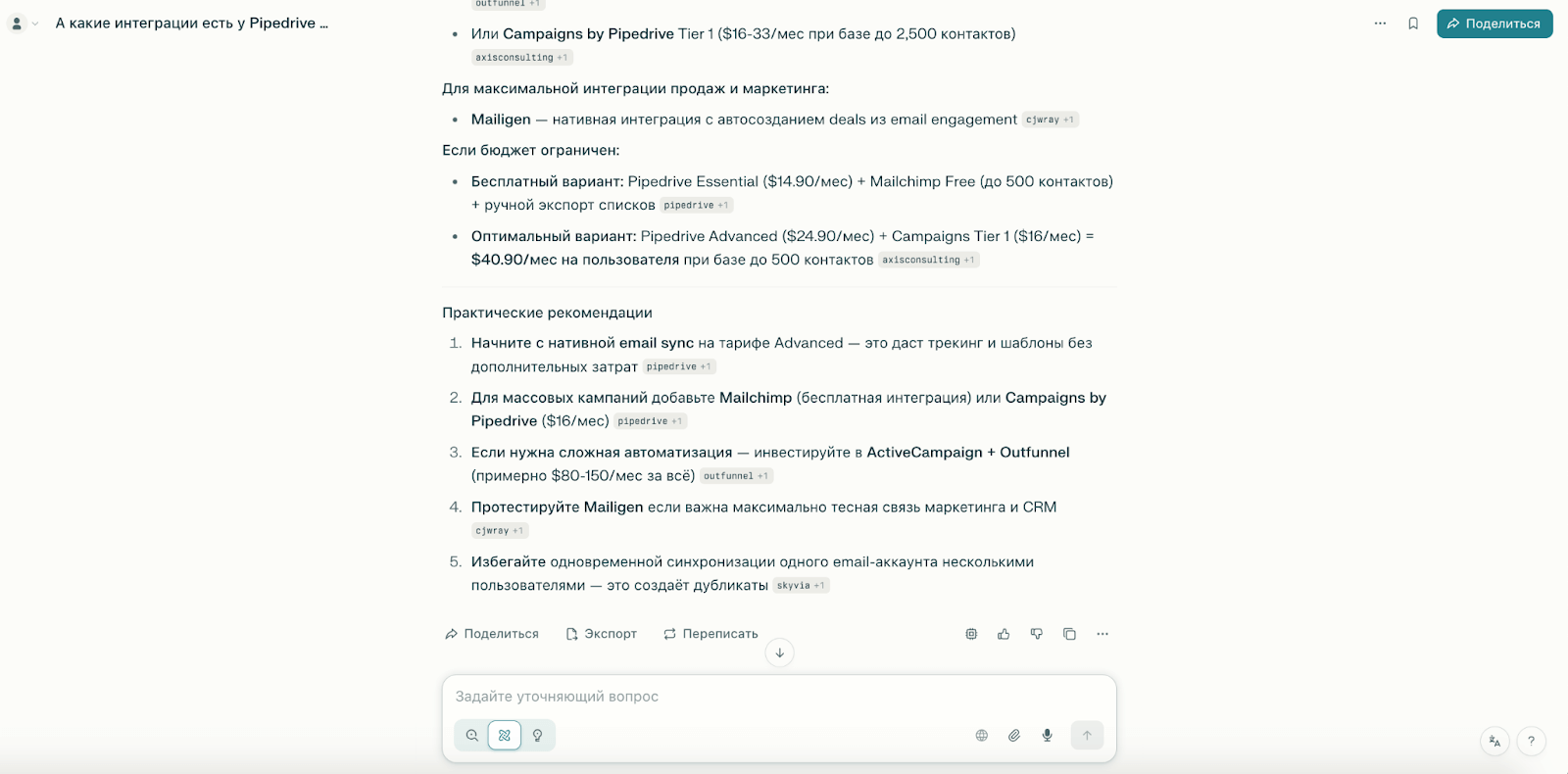
[Источник]
Шаг 5: Проверьте цитаты — убедитесь, что цены актуальны (кликните на источники и посмотрите даты публикации).
За 5 минут вы соберёте информацию, на которую раньше ушёл бы час ручного поиска.
Сохранение результатов
Если диалог получился полезным — сохраните его. Кликните на название Thread’а сверху и переименуйте во что-то осмысленное («Сравнение CRM 2025»). Он останется в вашей библиотеке, и вы всегда сможете вернуться.
[Источник]
Для более сложных проектов создайте Space — туда можно добавить несколько Thread’ов, загрузить файлы и пригласить коллег.
Первые шаги сделаны. Теперь посмотрим, как Perplexity применяется в реальной работе — от учёбы до бизнес-аналитики.
Сколько стоит умный поиск: тарифы и интеграции
Функционал понятен, кейсы изучены. Остался главный вопрос — сколько это стоит и какие варианты доступа существуют? Perplexity предлагает гибкую систему тарифов для разных задач и бюджетов.
Тарифные планы: от бесплатного до корпоративного
| План | Цена | Основные возможности | Для кого |
| Free | $0 | • Unlimited Quick Searches• 5 Pro Searches в день• Базовая модель Sonar• Сохранение истории | Новички, случайные пользователи |
| Pro | $20/мес<br>$200/год | • 300+ Pro Searches в день• GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro• Unlimited file uploads• Image generation• $5 месячный API кредит | Исследователи, аналитики, профессионалы |
| Education Pro | $4.99/мес | • Все возможности Pro• Требуется верификация через SheerID | Студенты и преподаватели университетов |
| Max | $200/мес<br>$2000/год | • Unlimited доступ к топ-моделям (GPT-4.1, Claude Opus 4, o3-Pro)• Unlimited Labs queries• Ранний доступ к Comet и новым фичам• Priority support | Power-юзеры, исследователи, контент-креаторы |
| Enterprise Pro | $40/мес на юзера<br>$400/год | • Всё из Pro + team management• Spaces для коллаборации• Internal knowledge search• SOC 2 Type II, GDPR compliance | Компании, команды от 10 человек |
| Enterprise Max | Custom pricing | • Всё из Enterprise Pro• Unlimited Labs и Research queries• 15 AI-видео/месяц• Priority support | Крупные организации с высокими требованиями |
Что входит в каждый план: детальное сравнение
Free план — это пробная версия, которая даёт понять, подходит ли вам Perplexity. Unlimited Quick Searches позволяют задавать простые вопросы без ограничений. 5 Pro Searches в день достаточно для экспериментов, но недостаточно для серьёзной работы.
Pro план — оптимальный выбор для большинства пользователей. Сотни Pro Searches в день означают, что вы не столкнётесь с лимитами даже при активном использовании. Доступ к топовым моделям (GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro) даёт гибкость — можете переключаться между моделями в зависимости от задачи. Unlimited file uploads критичны для работы с документами. Бонус: $5 месячного API кредита хватит на эксперименты с интеграциями.
Education Pro — выгодная сделка для студентов. За $4.99 в месяц получаете всё, что есть в Pro-плане за $20. Требуется подтверждение статуса через SheerID (обычно университетский email).
Max план — для тех, кто живёт в Perplexity. Unlimited Labs queries означают, что можно создавать сколько угодно дашбордов, отчётов, презентаций без ограничений. Доступ к самым продвинутым моделям (o3-Pro от OpenAI, Claude Opus 4) даёт преимущество в сложных аналитических задачах. Ранний доступ к Comet и новым фичам — бонус для тех, кто хочет быть на острие технологий.
Enterprise планы — для организаций. Главное отличие от персональных планов — не лимиты, а возможности коллаборации и безопасность. Spaces позволяют командам работать над проектами вместе, загружать внутренние документы, настраивать AI под специфику компании. SOC 2 Type II и GDPR compliance критичны для регулируемых индустрий (финансы, healthcare, юриспруденция).
API и интеграции: для разработчиков
Если вы хотите встроить Perplexity в свой продукт, есть Sonar API — платформа с pay-as-you-go моделью.
Тарифы Sonar API:
- Sonar (базовая версия): $5 за 1,000 searches + $1 за 750,000 слов input + $1 за 750,000 слов output
- Sonar Pro (продвинутая): $5 за 1,000 searches + $3 за 750,000 слов input + $15 за 750,000 слов output
Sonar Pro проводит несколько поисков на один запрос и даёт в два раза больше цитат, чем базовая версия. Цена менее предсказуема, но точность выше.
Интеграции: где ещё работает Perplexity
Помимо веб-интерфейса, Perplexity доступна через:
- Мобильные приложения — iOS и Android с полным функционалом, включая голосовой ввод
- Браузерные расширения — Chrome и Firefox для быстрого доступа из любой вкладки
- Desktop App — нативное приложение для macOS и Windows
- Comet Browser — экспериментальный AI-браузер, бесплатный с 2025 года (для Max-подписчиков ранний доступ)
- REST API — для встраивания в собственные продукты
Для Enterprise: интеграции с Google Drive, Dropbox, Box, OneDrive, SharePoint через app connectors. Можно подключить корпоративные файловые хранилища и искать внутри них наравне с веб-источниками.
Цены понятны, варианты доступа тоже. Но любой инструмент имеет ограничения. Давайте разберём, где Perplexity блестит, а где стоит быть осторожным.
Плюсы, минусы и риски
Любая технология имеет сильные стороны и слабые места. Perplexity не исключение. Разберём честно, где платформа выигрывает, а где нужно быть осторожным.
Сильные стороны:
- Свежие данные в реальном времени — информация обновляется постоянно, в отличие от статичных знаний обычных LLM
- Прозрачные ссылки на источники — каждое утверждение подкреплено цитатой, можно проверить факты за пару кликов
- Выбор моделей — GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro, o3-Pro в одном интерфейсе без переключения между сервисами
- Enterprise-уровень безопасности — SOC 2 Type II, GDPR compliance, данные не используются для обучения моделей
- Гибридный поиск — комбинация BM25, векторных embeddings и метаданных даёт лучший результат, чем чистый keyword-поиск или только векторы
Недостатки:
- Галлюцинации всё ещё случаются — особенно на модели R1, где частота ошибок в 18 раз выше, чем у других моделей. Всегда проверяйте критичную информацию через источники
- Непрозрачные лимиты — компания периодически меняет ограничения без чёткой коммуникации. Пользователи жалуются, что лимиты на Claude Opus были урезаны до 10 кредитов в день без предупреждения
- Зависимость от качества источников — если топовые результаты поиска низкого качества, ответ Perplexity тоже будет слабым
- Ключевые функции платные — безлимитный Copilot, загрузка файлов, Deep Research доступны только в платных планах
Практический совет: для критичных задач используйте правило трёх источников. Если Perplexity даёт ответ, проверьте его через два независимых канала (официальный сайт компании, правительственный ресурс, peer-reviewed статья). Если все три совпадают — информация надёжна.
Perplexity — мощный инструмент, но не универсальное решение. Понимая его ограничения и риски, вы используете платформу максимально эффективно и безопасно. Теперь посмотрим, куда движется индустрия AI-поиска и какую роль в этом играет Perplexity.
Будущее поисковых систем и роль Perplexity
Perplexity оказалась в правильном месте в правильное время. Компания строила answer engine с 2022 года, когда большинство думало, что Google непобедим. Сейчас даже сам Google вынужден копировать этот подход.
Search API и Async Tasks дают Perplexity шанс стать «бэкендом поиска» для других компаний. Zoom уже использует Sonar для своего AI-ассистента. Другие сервисы могут последовать.
Представьте: ваш CRM, таск-менеджер, корпоративный мессенджер — все подключены к Perplexity через API. Вы задаёте вопрос в Slack, а ответ приходит с цитатами из внутренних документов и веба. Это уровень интеграции, к которому движется рынок.
Perplexity позиционирует себя не как конечный продукт, а как инфраструктура для других разработчиков. Это умная стратегия — вместо того чтобы конкурировать с каждым приложением напрямую, стать их фундаментом.
Главное о Perplexity AI
Perplexity AI — это ответ-движок, который объединяет генеративные модели с поиском в реальном времени, выдавая структурированные ответы с цитатами вместо списка ссылок. Платформа построена на RAG-архитектуре и использует Vespa.ai для индексации миллиардов документов, комбинируя гибридный поиск (BM25 + векторы + метаданные) с топовыми LLM — от собственной Sonar до GPT-5, Claude и Gemini. Пользователи получают инструменты для разных задач: Quick Search для быстрых ответов, Pro Search с многошаговым рассуждением, Deep Research для полноценных отчётов за 2-4 минуты и Spaces для командной работы с файлами. Тарифы стартуют от бесплатного плана с 5 Pro-поисками в день до Enterprise Max с unlimited доступом ко всем функциям за custom pricing. Главные риски — галлюцинации моделей, юридические споры с издателями и непрозрачность некоторых лимитов, но компания ставит на прозрачность цитат и распределение выручки с создателями контента через Comet Plus.