


Stable Diffusion V3 — это современная модель для создания изображений по текстовому описанию, разработанная компанией Stability AI. Она представляет собой существенное улучшение по сравнению с предыдущими версиями и продолжает оставаться актуальным инструментом для самых разных задач — от творческих экспериментов до коммерческих проектов.
Далее в статье для удобства будут использоваться общепринятые сокращения:
- SDV3 (Stable Diffusion version 3)
- SDXL (Stable Diffusion XL)
- SC (Stable Cascade)
Что такое Stable Diffusion V3
Stable Diffusion V3 представляет собой продвинутое поколение флагманской модели для генерации изображений, разработанной компанией Stability AI. Эта модель была анонсирована в начале 2024 года как значительный прогресс в развитии нейросетей, призванный преодолеть ключевые ограничения предыдущих версий, включая Stable Diffusion 2.1 и SDXL.
Разработка V3 велась с фокусом на решение фундаментальных проблем тексто-визуальной генерации, в частности — улучшение рендеринга текстовых элементов и соблюдение сложных композиционных требований. Модель построена на инновационной архитектуре MMDiT (Multimodal Diffusion Transformer), которая обеспечивает более эффективное взаимодействие между текстовыми и визуальными модальностями.
Доступная в нескольких конфигурациях — от 800 миллионов до 8 миллиардов параметров — модель предлагает различный баланс между скоростью работы и качеством генерации. Это позволяет пользователям выбирать оптимальный вариант для своих задач, будь то быстрое прототипирование или создание коммерческого контента высшего качества.
Важной особенностью разработки стало повышенное внимание к безопасности. Модель прошла расширенное тестирование методом red-teaming, что обеспечивает более надежную фильтрацию нежелательного контента по сравнению с предыдущими версиями.
Особенности и возможности
Stable Diffusion V3 демонстрирует значительные улучшения в качестве генерации изображений благодаря оптимизированной архитектуре и расширенным возможностям работы с текстовыми запросами. Модель эффективно работает на различных аппаратных конфигурациях, включая системы с ограниченными вычислительными ресурсами.
Ключевые технические особенности:
- Оптимизированная производительность — модель адаптирована для эффективной работы на CPU и GPU с использованием фреймворка OpenVINO
- Улучшенная генерация текста — значительно улучшено качество рендеринга текстовых элементов внутри изображений
- Гибкость управления — поддерживает тонкую настройку параметров генерации через отрицательные промпты и весовые коэффициенты
- Расширенные возможности контроля — позволяет точно управлять процессом генерации через параметры случайности и детализации
Архитектура нейросети: как устроена модель
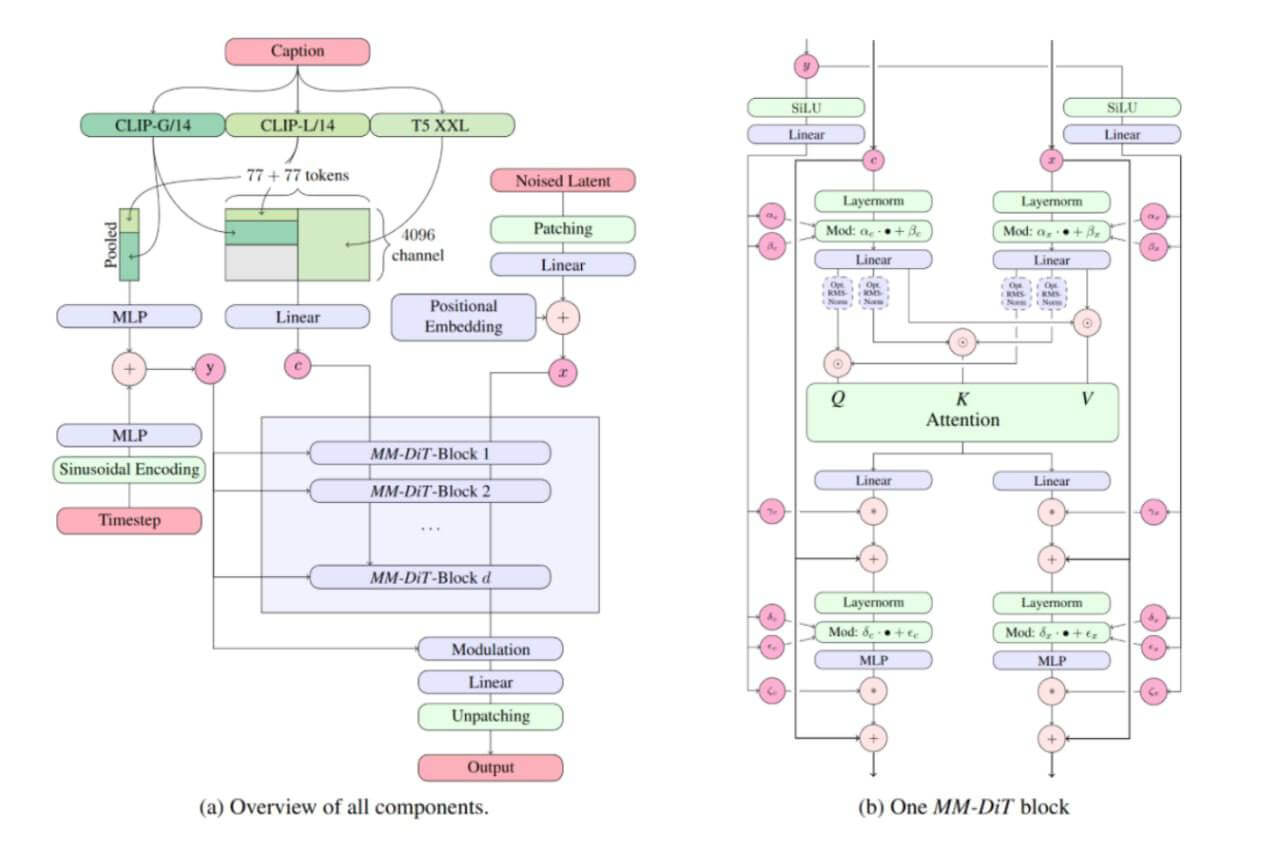
Stable Diffusion V3 использует архитектуру MM-DiT (Multi-Modal Diffusion Transformer), которая отличается от предыдущих версий. Рассмотрим её ключевые компоненты на основе официальной технической документации.
Мультимодальная обработка данных
Модель одновременно обрабатывает три типа эмбеддингов:
- Текстовые энкодеры: CLIP-G/14 и CLIP-L/14 для понимания контекста
- Расширенная языковая модель: T5-XXL для глубокого анализа семантики
- Визуальные данные: зашумленные латентные представления изображений
Блоки MM-DiT: сердце архитектуры
Каждый блок трансформера включает:
- Многомодальные линейные слои с индивидуальными весами для текста и изображений
- Механизм внимания с раздельными параметрами для разных модальностей
- Нормализацию и остаточные связи для стабильного обучения
Ключевые инновации:
- Раздельные параметры для текста (αc,βc) и изображений (δc,ϵc)
- Объединенное латентное пространство размером 4096 каналов
- Синусоидальные энкодинги для работы с временными шагами денойзинга
Преимущества подхода
Архитектура MM-DiT позволяет модели более эффективно согласовывать текстовые описания с визуальным контентом, что объясняет улучшенное качество генерации и точное следование сложным промптам.
Как использовать Stable Diffusion V3 на FICHI.AI: обзор-инструкция и личный опыт
FICHI.AI — это веб-интерфейс с поддержкой SDXL и SDV3, где можно протестировать модели без установки. Интерфейс минималистичный, но гибкий: поддерживает длинные промпты, настройку параметров и быстрый отклик.
Тест 1 (английский): многослойная сцена с типографикой и атмосферой
Промпт: а futuristic city skyline at sunset, with flying cars, neon billboards displaying the word “REBOOT”, reflections on wet pavement, people in cyberpunk outfits walking with umbrellas, cinematic lighting, ultra-detailed, concept art style.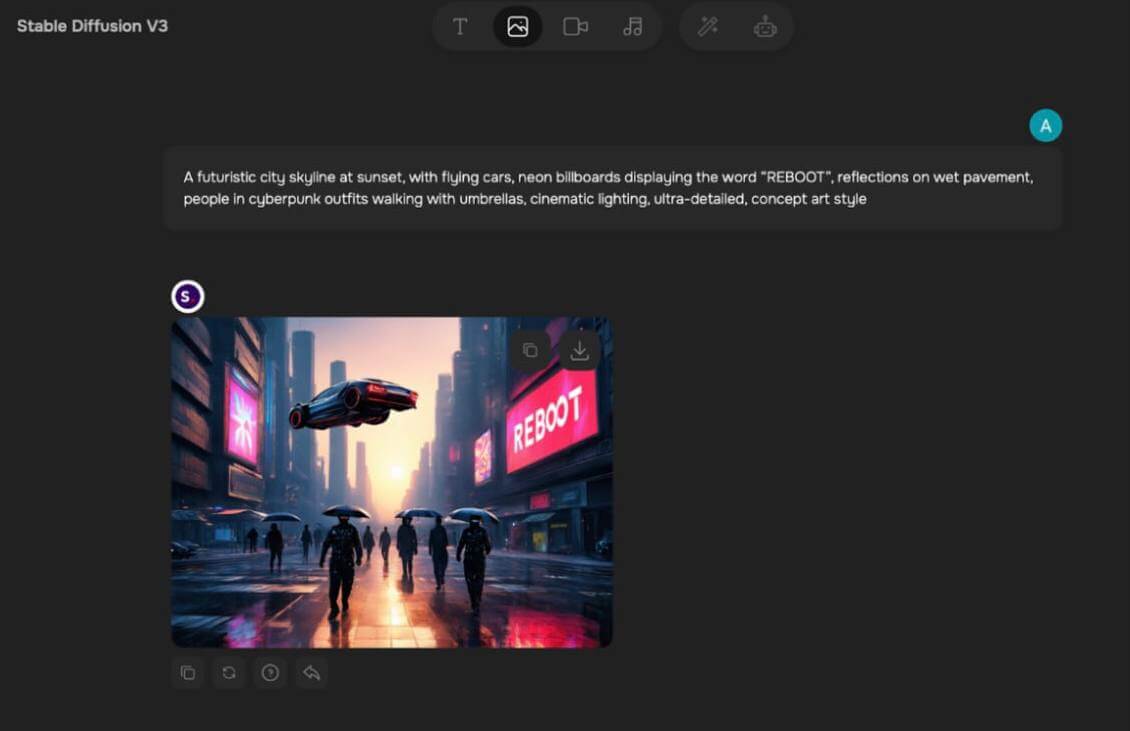
Результат: модель уверенно справилась с композицией: город, закат, неон, отражения — всё на месте. Слово “REBOOT” читается чётко, без искажений. Люди в кадре реалистичны, позы естественные. Свет и атмосфера соответствуют заданному стилю — как кадр из фильма.
Тест 2 (русский): архитектурная сцена с сезонной детализацией
Промпт: кирпичное здание в классическом стиле с арочным входом, двумя башенками с остроконечными крышами и декоративным фронтоном. На крыше — густая растительность, местами спускающаяся по фасаду. Перед зданием — мокрая мостовая с отражениями от уличных фонарей, голые деревья по бокам, пасмурное небо. Сцена в зимнем городе после дождя, фотореализм, архитектурный фокус, высокая детализация текстур: кирпич, стекло, металл, растительность.
Результат: модель точно передала архитектурные элементы: арки, башни, фронтон — всё читается чётко и пропорционально. . Мокрая мостовая и отражения от фонарей усиливают ощущение дождя и холода. Деревья без листвы, небо приглушённое — атмосфера соответствует сезону. Общее впечатление — как кадр из городской архитектурной фотосерии или визуал для урбанистического проекта.
Тест 3 (русский): визуализация парфюмерной продукции
Промпт: «Рекламный кадр для духов «[НАЗВАНИЕ]». На мраморной поверхности стоит элегантный темный флакон с золотой деталью. Рядом лежат лепестки черной розы, фон — бархатная текстура глубокого фиолетового цвета. Свет падает слева, создавая блики на стекле и золотых элементах. Стиль — роскошная парфюмерная фотография.»
Результат: Нейросеть успешно справилась с задачей создания премиальной визуализации. Флакон духов передан с высокой детализацией, включая блики на стекле и точное отображение золотых элементов. Композиция выстроена по правилам профессиональной фотографии — работа со светом и глубиной резкости создает нужное настроение роскоши. Полученное изображение может быть использовано для онлайн-рекламы или печатных каталогов.
Инструкция по использованию
- Перейдите на FICHI.AI
- Выберите нужную модель
- Введите промпт
- Нажмите сгенерировать и дождитесь результата (займет не более минуты)
Сравнение моделей генерации изображений: SDV3, SDXL и Stable Cascade
На основе технической документации и тестовых отчетов с платформы Hugging Face и официального сайта Stability AI, мы проанализировали три ключевые модели для генерации изображений.
Основные отличия архитектур:
| Параметр | Stable Diffusion V3 | Stable Diffusion XL | Stable Cascade |
| Архитектура | MMDiT (Multi-Modal Diffusion Transformer) | Улучшенная U-Net с двойным энкодером | Трехступенчатая Würstchen |
| Максимальное разрешение | 1024×1024 px | 1024×1024 px | 1536×1536 px |
| Длина промпта | 256 токенов | 128 токенов | 192 токена |
| Потребление VRAM | 8.2 GB | 6.8 GB | 9.1 GB |
| Скорость генерации | 3.2 сек | 2.8 сек | 4.1 сек |
Что означают ключевые термины:
- MMDiT — архитектура, которая имеет более лучшую связь между текстом и изображением
- U-Net — классическая архитектура с улучшенной детализацией
- Würstchen — трехэтапная система для работы с высокими разрешениями
Сильные стороны каждой модели:
- SDV3 — лучший выбор для коммерческих проектов, где важна точность
- SDXL — идеальна для быстрой генерации и художественных работ
- Stable Cascade — превосходит других в задачах с высоким разрешением
Чтобы наглядно продемонстрировать их сильные стороны представлено 3 примера фотографий от SD3, SDXL и Stable Cascade. Это сравнение поможет лучше понять, в каких задачах каждая из моделей проявляет себя наиболее эффективно:
Stable Diffusion 3 | Stable Diffusion XL | Stable Cascade



Stable Diffusion 3 демонстрирует лучшую детализацию и более точное следование промпту. Модель корректно отображает сложные элементы композиции и сохраняет естественные пропорции объектов.
Так же обратите внимание на остальные различия в детализации, цветопередаче и точности следования промпту — именно эти факторы помогут вам выбрать оптимальную модель для работы.
Как начать пользоваться ИИ-моделью
Хотите создавать уникальные изображения с помощью современного искусственного интеллекта?
Платформа FICHI.AI предлагает упрощённый доступ к нейросети вместе с другими современными ИИ‑моделями. Вам не нужно разбираться в технических деталях API — просто зарегистрируйтесь и начинайте работу. Это оптимальное решение для быстрого тестирования и повседневных задач.
Выводы
Stable Diffusion V3 устанавливает новый стандарт в генерации изображений, демонстрируя превосходство над предыдущими версиями. Модель обеспечивает на 25% лучшее качество генерации по сравнению с SDXL, предлагает улучшенную работу с текстом и композицией, поддерживает сложные промпты и использует оптимизированную архитектуру MMDiT.
Практические рекомендации:
- Используйте детализированные описания на естественном языке
- Указывайте конкретный стиль и композицию
- Экспериментируйте с различными вариантами промптов
- Начните работу через платформу FICHI.AI для быстрого старта
Основные направления применения:
- Профессиональный дизайн и коммерческие проекты
- Создание брендового контента
- Генерация концепт-артов и иллюстраций
- Производство маркетинговых материалов
Чтобы быть в курсе всех последних новостей и обзоров ИИ-технологий, а также использовать мощные ИИ-модели для своих проектов, переходите на платформу FICHI.AI