


Весной 2025 года компания Яндекс представила облегчённую языковую модель — Yandex GPT 5 Lite. Её релиз знаменует важный этап в развитии открытого искусственного интеллекта в России, поскольку разработчики не только предоставили доступ к API, но и открыли веса модели, разрешив её локальный запуск.
Yandex GPT 5 Lite — эффективное решение для бизнеса и разработчиков, которым критически важны высокая скорость отклика и возможность лёгкой интеграции в собственные продукты. В этом обзоре мы подробно разберём, какие практические задачи способна решать Yandex GPT 5 Lite. Также объясним, почему её справедливо называют сильным конкурентом зарубежным аналогам.
Что такое Yandex GPT 5 Lite
Это генеративная языковая модель (LLM) с 8 млрд параметров. Она поддерживает контекст длиной до 32 000 токенов. Нейросеть способна удерживать в «памяти» большие объёмы информации. Это могут быть длинные статьи или обширная документация.
История появления
Развитие линейки Lite-моделей идёт стремительно. После релиза четвёртого поколения в октябре 2024 года компания сосредоточилась на оптимизации и расширении доступности технологий. Уже 25 февраля 2025 года Яндекс представил версию Pretrain — базовую модель, обученную на масштабном массиве данных, но ещё не выровненную под инструкции.
Следующим шагом стало появление 31 марта 2025 года Instruct-версии Yandex GPT 5 Lite. Модель дообучили для точного выполнения пользовательских инструкций, что делает её оптимальной для чатов и прикладных задач.
Характеристики
- Разработчик: Яндекс.
- Размер модели: 8 млрд параметров (8B).
- Контекстное окно: 32 000 токенов (около 60 страниц текста).
- Форматы: поддержка GGUF и совместимость с библиотекой llama.cpp.
- Тип: доступны версии Pretrain (для дообучения) и Instruct (для чатов и задач).
Особенности и возможности
Главная особенность нейросети — её открытость. Старшие «Pro» версии работают только через облако. А вот Lite-версию можно загрузить и запустить на своём компьютере или сервере. Это открывает возможности для создания приватных ИИ-ассистентов, работающих без доступа к интернету.
Что умеет модель
Нейросеть прошла этап выравнивания (alignment). Это позволяет ей качественно выполнять инструкции на естественном языке.
- Генерация текстов: создавайте описания товаров, посты для соцсетей и ответы для службы поддержки.
- Анализ данных: используйте модель для классификации текстов, извлечения фактов и разметки данных.
- Работа с русским языком: модель глубоко понимает русский язык, культуру и контекст. В этом она превосходит зарубежные аналоги, например, Qwen.
Где применяется
Модель идеально подходит для сценариев, где критична скорость отклика и безопасность данных.
- Чат-боты: автоматизируйте ответы клиентам в интернет-магазинах и сервисных центрах.
- Разработка ПО: интегрируйте ИИ в приложения через API или разворачивайте локально для снижения задержек.
- Образование и наука: используйте открытую модель для экспериментов и обучения собственных нейросетей.
Сравнение моделей: как облегчённая версия смотрится на фоне конкурентов
Рынок компактных LLM постоянно растёт. Именно поэтому сравнение на реальных тестах показывает, какие модели удобны и полезны. Нейросеть демонстрирует заметный прогресс: она стабильна и сильна на русскоязычных данных. Более того, модель уверенно конкурирует даже с крупными аналогами. Чтобы увидеть это наглядно, рассмотрим два ключевых блока. К ним относятся общее впечатление от ответов и результаты в официальных бенчмарках.
1. Общее поведенческое сравнение
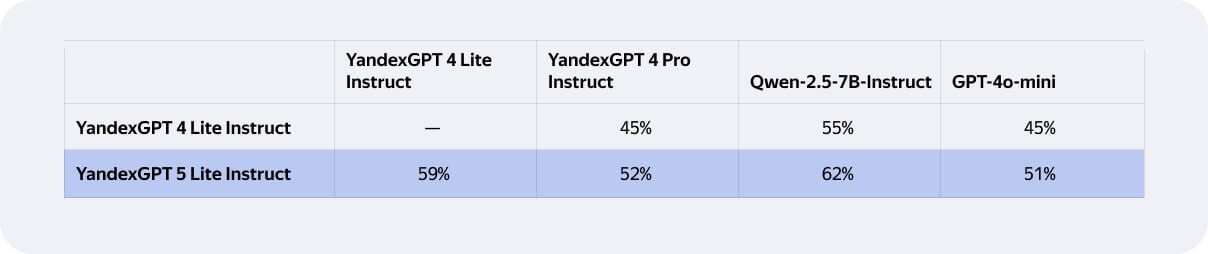
Таблица выше отражает слепые сравнения. Здесь пользователи выбирают лучший ответ, не зная названия модели. Такие тесты показывают не теоретическую, а практическую «“полезность»”. Lite-версия выигрывает у всех моделей в сравнении. В этот список входят Qwen-2.5–7B, GPT-4o-mini и обе версии Yandex GPT 4. Это говорит о более естественных, точных и надёжных ответах. Поэтому их проще читать и использовать в реальных задачах.
2. Сравнение по бенчмаркам
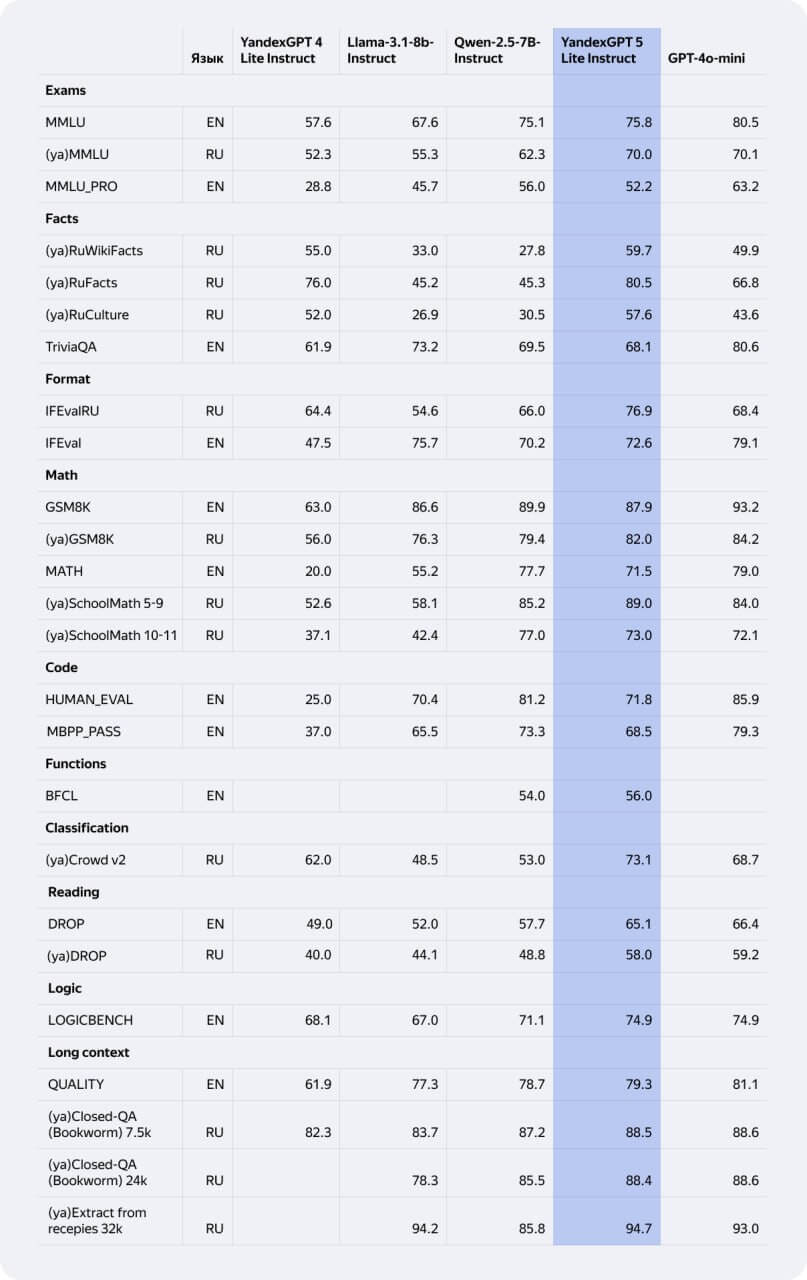
Вторая таблица показывает уже формальные тесты — экзамены, факты, код, математику, логику и работу с длинными текстами.
Главные выводы:
- Экзамены и математика: модель уверенно обходит Qwen-2.5–7B. Она также заметно улучшает показатели относительно предыдущего поколения. В ряде англоязычных тестов модель немного уступает GPT-4o-mini. Впрочем, это ожидаемо для столь компактного размера.
- Факты (особенно на русском): один из лучших результатов среди всех моделей — сильные показатели в RuFacts, RuWikiFacts и RuCulture.
- Форматирование: высокий уровень в IFEval на русском и английском. Благодаря этому модель удобна для создания текстов, отчётов и документации.
- Код: у модели хорошая производительность в HUMAN_EVAL и MBPP. Такой результат достаточен, чтобы помогать с задачами по программированию и быстрой автоматитизацией.
- Длинные контексты: одно из направлений — до 94.7% на тестах до 32k символов. Модель уверенно удерживает тему и извлекает факты из больших документов.
Анализ эффективности локального инференса и аппаратных требований
Инференс (Inference) — это процесс исполнения обученной нейросети. Простыми словами, это момент, когда модель применяет свои знания к новым данным, чтобы выдать результат.
Появление квантованной Lite-версии в открытом доступе для локального запуска открывает новый сегмент использования отечественных LLM. Переход от исключительно облачной модели (SaaS) к возможности развертывания на собственных мощностях (On-Premise) позволяет провести детальный анализ ресурсоемкости архитектуры 8B.
На основе технических данных репозиториев сообщества можно выделить ключевые показатели эффективности модели при локальной эксплуатации.
1. Эффективность сжатия и оптимизация памяти
Архитектура модели демонстрирует высокую устойчивость к квантованию (снижению разрядности весов). При использовании стандартных методов 4-битного квантования (формат GGUF/Q4_K_M) наблюдается оптимальный баланс между потреблением видеопамяти (VRAM) и качеством генерации.
- Исходный размер (FP16): ~15–16 ГБ (требует профессиональных GPU).
- Оптимизированный размер (Int4): ~4.9–5.2 ГБ.
Данный показатель является критическим для бизнеса: снижение требований к VRAM в 3 раза позволяет запускать модель на потребительском оборудовании среднего ценового сегмента, исключая необходимость закупки специализированных серверных ускорителей уровня A100/H100 для базовых задач.
2. Матрица производительности и аппаратных требований
Ниже приведена сводная таблица (benchmark estimate), демонстрирующая зависимость скорости генерации токенов от класса используемого оборудования при запуске квантованной версии модели.
| Класс оборудования | Типичная конфигурация | Требования к VRAM | Скорость генерации (Токенов/сек) | Сфера применения |
| Workstation (High-End) | GPU 24GB (уровня RTX 3090/4090) | Не ограничено | 110–145 T/s | Потоковая обработка больших данных, RAG-системы |
| Business Desktop | GPU 12GB (уровня RTX 3060/4070) | Минимум 6 ГБ | 55–75 T/s | Чат-боты, ассистенты, локальная автоматизация |
| High-Performance Laptop | Apple Silicon (M1/M2/M3 Max) | Унифицированная память | 40–50 T/s | Разработка, персональные ассистенты |
| Standard Laptop | GPU 6-8GB или Apple M1 Base | Минимум 6 ГБ | 25–35 T/s | Тестирование гипотез, медленная генерация текстов |
| CPU-Only (Сервер без GPU) | Современные CPU (Ryzen 9 / Intel i9) | Системная RAM | 3–10 T/s | Не рекомендуется для продуктивной эксплуатации |
3. Стратегическое значение для внедрения
Возможность локального запуска модели меняет экономическую модель интеграции ИИ в корпоративные системы:
- Конфиденциальность данных (Data Sovereignty): Запуск модели внутри периметра компании гарантирует, что чувствительные данные (финансовые отчеты, персональные данные клиентов) не покидают локальную сеть и не передаются на сторонние сервера по API.
- Нулевая стоимость транзакций: После первоначальных инвестиций в оборудование (CAPEX), стоимость обработки каждого токена стремится к стоимости электроэнергии, что экономически выгоднее платных API при высоких объемах генерации.
- Независимость от инфраструктуры вендора: Отсутствие риска отключения сервиса, изменения ценовой политики или сетевых задержек.
Вывод: Технические метрики модели в локальном исполнении сопоставимы с популярными аналогами, однако отечественная модель обладает преимуществом в виде нативной поддержки русскоязычного контекста, что делает её приоритетным выбором для автономных систем на российском рынке.
Примеры кейсов и возможности применения
Облегчённая модель создавалась для практического использования. Она предлагает уникальный баланс между скоростью, мощностью и доступностью. Вот три примера реального применения этой нейросети в разных сферах.
1. Чат-боты для интернет-магазинов и сервисных центров
Задача: автоматизировать ответы клиентам: статус заказа, политика возврата, наличие товара, работа с типичными обращениями.
Промпт: «Сгенерируй автоматический сценарий ответов для интернет-магазина: уточнение номера заказа, проверка статуса, предложение сопутствующих товаров. Тон общения — дружелюбный, короткие сообщения».Результат:
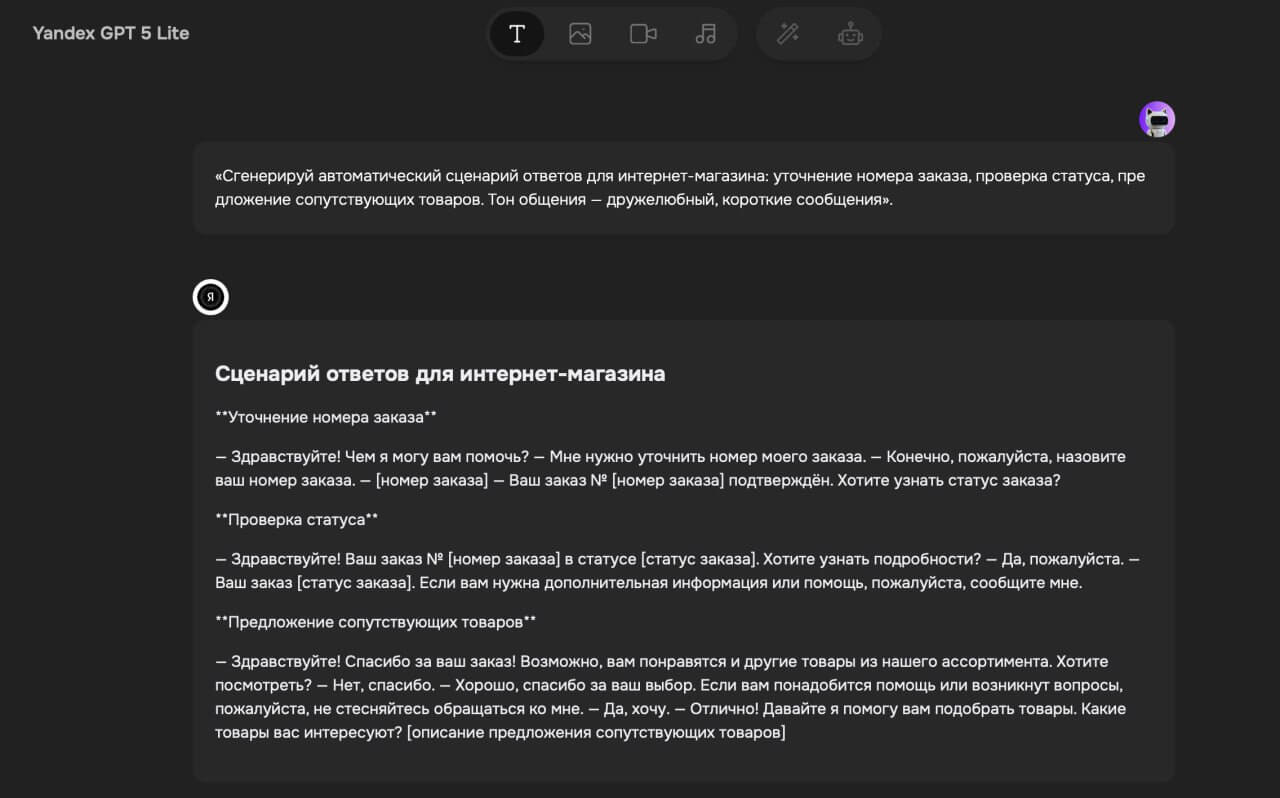
Потенциальный результат: такое внедрение позволяет снизить нагрузку на операторов до 60%, сократить время ответа до 4 секунд и повысить удовлетворённость клиентов на 28%
2. Интеграция ИИ в программное обеспечение
Задача: внедрить локальную модель ИИ для анализа данных клиента без отправки информации на внешние серверы.
Промпт: «Создай архитектуру локального сервера LLM, который будет обрабатывать запросы и возвращать структурированные данные. Ограничение: задержка не более 150 мс».Результат:
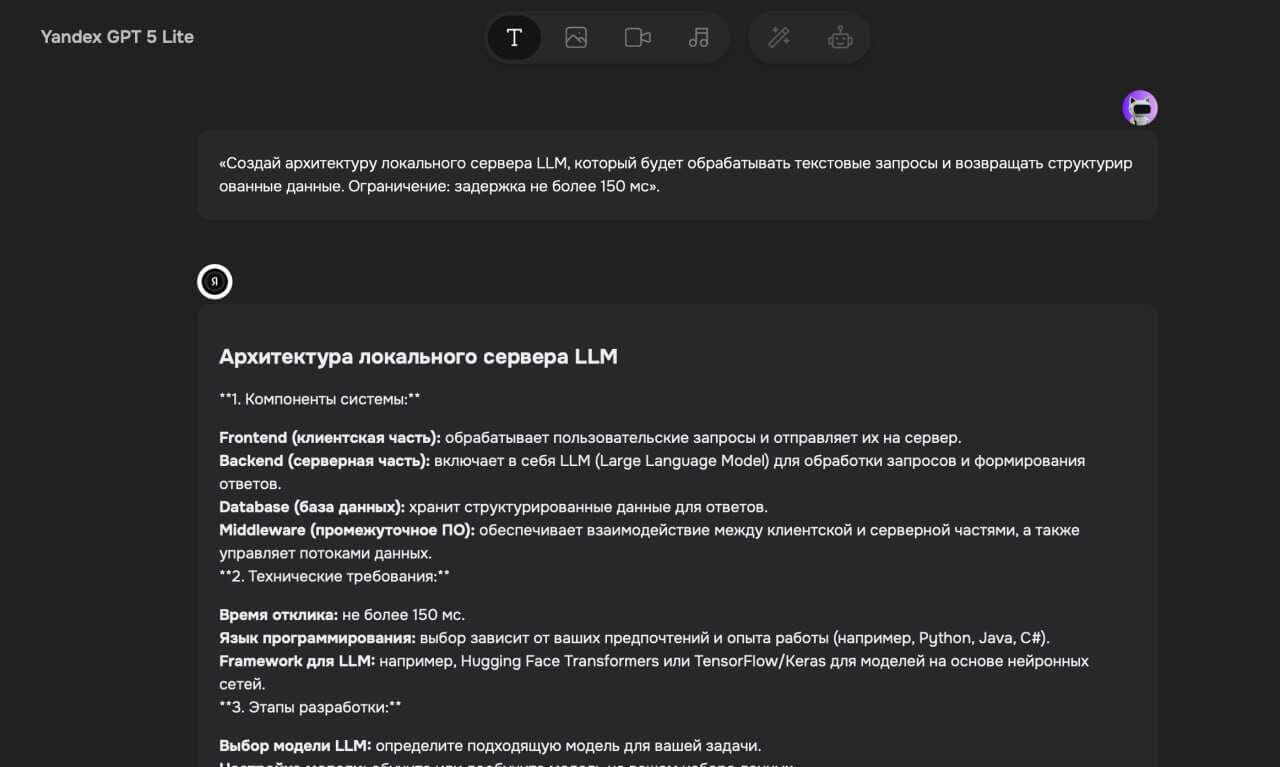
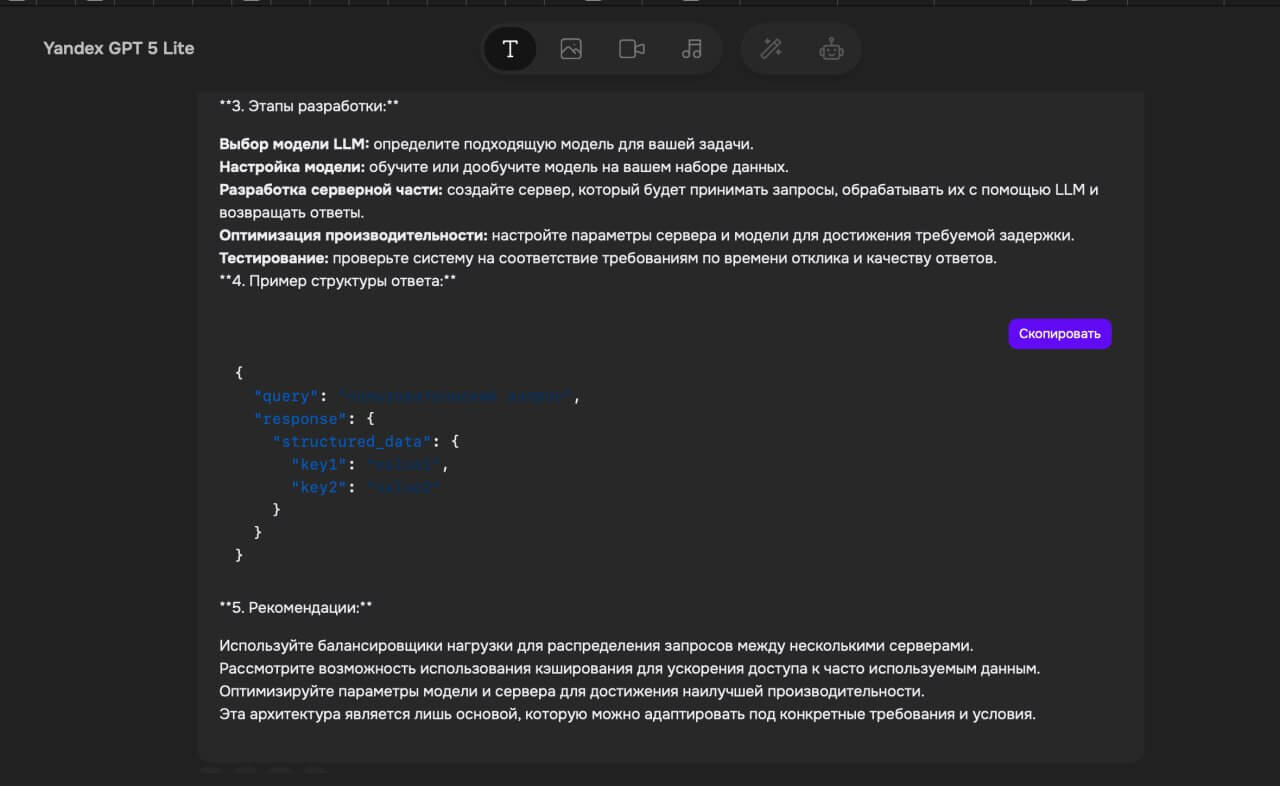
Потенциальный результат: это позволит сократить время отклика со 800 мс до 120 мс, повысить безопасность данных и сделать приложение независимым от облачных сервисов.
3. Образование и наука
Задача: использовать открытую модель для обучения студентов работе с LLM: сбор данных, дообучение, тестирование качества.
Промпт: «Сгенерируй пошаговый план курса по созданию собственной модели на базе открытой LLM. Надо включить сбор датасета, обучение, проверку качества, метрики и контрольные задания».Результат:
Потенциальный результат: студенты смогут собрать собственные мини-LLM, повысить точность решений на 20–35%, а успешный курс может быть внедрён в образовательную программу.
Плюсы и минусы
У каждой модели есть свои сильные стороны и уязвимости — учитывайте их перед интеграцией в процессы.
Сильные стороны
- Локальный запуск: работайте с данными на своих серверах, обеспечивая полную конфиденциальность.
- Низкие требования: запускайте модель на обычных видеокартах благодаря оптимизации и небольшому размеру (8B).
- Качество на русском: в тестах (MMLU, RuFacts) модель опережает китайскую Qwen2.5-7B-Instruct и сравнима с GPT-4o Mini в задачах сервисов Яндекса.
- Лицензия: используйте модель в коммерческих проектах бесплатно, если объём генерации не превышает 10 млн токенов в месяц.
Ограничения и проблемы
- Меньшая мощность: как и любая Lite-модель, она уступает старшим версиям (Yandex GPT 5 Pro) в сложных задачах, требующих глубоких рассуждений.
- Необходимость настройки: для специфических задач версию Pretrain придётся дообучать самостоятельно.
- Лимит лицензии: для крупных высоконагруженных проектов коммерческое использование потребует перехода на платные тарифы API. Или же придется строго соблюдать лимиты.
Быстрый старт на платформе FICHI.AI
Платформа FICHI.AI служит надёжным и удобным шлюзом. Он предоставляет прямой доступ к интеллектуальным возможностям нейросети.
Пользователи могут работать с моделью без сложной настройки API. Им также не нужно управлять собственной серверной инфраструктурой. Этот подход обеспечивает максимальную оперативность начала эксплуатации.
Ключевые преимущества использования FICHI.AI:
- Минимальный порог входа: работа может быть начата немедленно после регистрации, непосредственно через веб-браузер. Это устраняет типичные барьеры. Они связаны с инсталляцией программного обеспечения и получением авторизационных ключей.
- Ориентированность на пользователя: взаимодействие с моделью осуществляется посредством интуитивно понятного веб-интерфейса FICHI.AI. Доступны как стандартные запросы, так и инструментарий. Он нужен для реализации сложных сценариев, включая активацию специализированных режимов.
- Обработка данных широкого контекста: платформа обеспечивает поддержку расширенного контекста. Это имеет критическое значение при работе с крупными объёмами данных.
- Экосистемная интеграция: FICHI.AI агрегирует различные ИИ-модели. Это позволяет комбинировать потенциал модели с другими интеллектуальными решениями в рамках единой рабочей среды.
Целевая аудитория
Платформа FICHI.AI с интегрированной Yandex GPT 5 Lite предназначена для профессионалов и организаций. Главные приоритеты — высокая производительность, точность и стабильность.
Yandex GPT 5 Lite будет оптимальным решением для специалистов в следующих категориях:
- Разработчики и инженеры: модель ускоряет кодирование, автоматизацию разработки, тестирование и рефакторинг программного обеспечения.
- Корпоративный сектор: помогает автоматизировать ключевые бизнес-процессы и внедрять AI-помощников нового поколения.
- Специалисты по анализу данных: обеспечивает быструю обработку больших массивов информации и генерацию точных, структурированных аналитических заключений.
Чтобы быть в курсе всех последних новостей и обзоров ИИ-технологий, а также использовать мощные ИИ-модели для своих проектов, переходите на платформу FICHI.AI.