


Gemini Flash — это семейство мультимодальных моделей искусственного интеллекта от Google DeepMind. Они созданы для работы с большими объёмами данных при минимальных затратах. Модель обрабатывает текст, изображения, видео и аудио, сохраняя высокую скорость ответов. Flash подходит для бизнеса и разработчиков, которым нужна производительность без лишних расходов. Это рабочая лошадка среди моделей Google — надёжная, быстрая и доступная.
Что такое Gemini Flash
Место в семействе Gemini

Gemini Flash занимает среднюю позицию в линейке моделей Google. Она находится между флагманом Pro и облегчённой версией Flash-Lite. Google представила первую версию Flash в 2024 году как часть обновления Gemini 1.5. Модель быстро стала самой популярной среди разработчиков благодаря балансу цены и качества.
В декабре 2024 года вышла Gemini 2.0 Flash с улучшенной производительностью и новыми возможностями. Эта версия превзошла предшественницу Gemini 1.5 Pro по ключевым показателям. При этом она работала в два раза быстрее. В 2025 году Google выпустила Gemini 2.5 Flash — текущую стабильную версию. Она получила режим мышления и улучшенные возможности для агентских приложений.Семейство Gemini включает несколько уровней моделей. На вершине находится Gemini Pro — самая мощная модель для сложных задач с глубокой аналитикой. Flash работает быстрее и дешевле, сохраняя высокое качество для большинства задач. Flash-Lite — самый экономичный вариант для массовых операций с жёсткими требованиями к скорости.
Основная идея модели
Google создала Flash для высоконагруженных приложений, где важна скорость обработки больших объёмов запросов. Модель оптимизирована для работы в масштабе — она справляется с тысячами запросов в минуту без потери качества. Это делает Flash идеальным выбором для продуктовых команд и стартапов.
Flash использует архитектуру смеси экспертов (MoE). Она активирует только нужные части модели для конкретной задачи. Такой подход снижает вычислительные затраты и ускоряет работу. Модель обрабатывает запросы со скоростью более 250 токенов в секунду — это в два раза быстрее, чем у конкурентов.
Ключевая особенность Flash — мультимодальность без компромиссов. Модель одинаково хорошо работает с текстом, изображениями, аудио и видео. Вы можете загрузить документ с графиками, задать вопрос голосом и получить ответ с иллюстрациями — всё в одном запросе. Это упрощает разработку сложных приложений.
Версии Flash (2.0, 2.5, Flash-Lite)
Gemini 2.0 Flash появилась в декабре 2024 года как экспериментальная модель. Она стала общедоступной в феврале 2025 года. Версия включает встроенную работу с инструментами — модель сама вызывает поиск Google, выполняет код и использует пользовательские функции. Версия 2.0 Flash поддерживает генерацию изображений и преобразование текста в речь прямо внутри диалога.
Gemini 2.5 Flash вышла в апреле 2025 года и стала первой моделью Flash с режимом мышления. В этом режиме модель показывает процесс рассуждений перед ответом. Это повышает качество решения сложных задач. Версия 2.5 улучшила показатели в программировании — на 5% выросла точность в бенчмарке SWE-Bench Verified по сравнению с предыдущим релизом.
Flash-Lite — облегчённая версия для задач с высокой нагрузкой и жёсткими требованиями к стоимости. Модель работает так же быстро, как основная Flash, но стоит дешевле. Flash-Lite обрабатывает около 40 000 изображений с подписями меньше чем за доллар в платном тарифе Google AI Studio. Эта версия подходит для массовой обработки данных — классификации, суммаризации, извлечения информации.
Все версии Flash поддерживают контекстное окно в 1 млн токенов — это примерно 800 000 слов или несколько часов видео. Gemini 2.0 Pro Experimental увеличивает окно до 2 млн токенов, но это экспериментальная модель с ограниченным доступом. Для большинства задач возможностей Flash достаточно.
Ключевые возможности
Мультимодальность (текст, изображения, аудио, видео)
Gemini Flash обрабатывает четыре типа данных — текст, изображения, аудио и видео — в одном запросе. Вы загружаете файлы любого формата, и модель понимает контекст между ними. Например, Flash анализирует презентацию с графиками, читает текст на слайдах и отвечает на вопросы по содержанию.
Для изображений модель распознаёт объекты, текст, лица и сцены. Flash читает рукописные заметки, извлекает данные из таблиц на фотографиях и описывает содержимое инфографики. Версия Gemini 2.5 Flash Image умеет не только анализировать, но и генерировать изображения — создаёт иллюстрации по описанию, редактирует существующие картинки и объединяет несколько изображений в одно.
Аудио обрабатывается с высокой точностью — модель транскрибирует речь на нескольких языках, определяет говорящих и понимает эмоциональную окраску. Flash поддерживает генерацию речи с управляемой интонацией — можно задать акцент, тон голоса и эмоциональную окраску через текстовые команды. Модель переключается между 24 языками, сохраняя один и тот же голос.
Видео анализируется покадрово с учётом звукового ряда. Flash извлекает ключевые моменты из записей, создаёт таймкоды для навигации и генерирует субтитры. Модель обрабатывает видео со скоростью 258 токенов на секунду при частоте один кадр в секунду. Это позволяет работать с длинными записями — лекциями, вебинарами, интервью — без предварительной обработки.
Контекстное окно в 1 млн токенов
Контекстное окно определяет объём информации, с которым модель работает одновременно. Gemini Flash поддерживает 1 048 576 входных токенов — это эквивалент нескольких сотен страниц текста, часов видео или тысяч изображений. Такой объём позволяет анализировать целые книги, годовые отчёты компаний или многочасовые записи совещаний в одном запросе.
Большое контекстное окно упрощает работу с корпоративными данными. Вы загружаете все релевантные документы сразу — контракты, переписку, технические спецификации — и задаёте вопросы по всему массиву. Flash находит нужную информацию, сопоставляет данные из разных источников и формирует связные ответы. Это быстрее, чем работать с документами по отдельности.
Для кода контекстное окно означает возможность анализировать целые репозитории. Flash просматривает десятки файлов проекта, понимает архитектуру приложения и предлагает изменения с учётом всей кодовой базы. Модель отслеживает зависимости между модулями и предупреждает о потенциальных конфликтах при рефакторинге.
Выходное ограничение составляет 65 536 токенов — примерно 50 000 слов. Этого достаточно для развёрнутых отчётов, технических документов и подробных анализов. Если нужен более короткий ответ, можно задать ограничение в промпте. Flash сохраняет качество независимо от длины ответа.
Встроенные инструменты и функции
Gemini Flash нативно вызывает внешние инструменты без дополнительной настройки. Модель использует поиск Google для получения актуальной информации, выполняет Python-код для вычислений и вызывает пользовательские функции через API. Это превращает Flash в агента, который сам выбирает нужные инструменты для решения задачи.
Функциональные вызовы работают через описание доступных функций в JSON-схеме. Вы указываете название функции, параметры и описание — Flash понимает, когда применить каждую функцию. Модель может вызывать несколько функций последовательно, передавая результаты между ними. Это полезно для многошаговых задач — сбора данных, обработки и формирования отчёта.
Встроенное выполнение кода позволяет Flash делать сложные вычисления и работать с данными. Модель пишет Python-скрипты, запускает их и использует результаты в ответе. Например, Flash анализирует CSV-файл с продажами, строит графики трендов и формулирует выводы — всё автоматически. Код выполняется в изолированной среде с ограничениями по времени и ресурсам.
Поиск Google интегрирован напрямую — Flash самостоятельно решает, когда нужна актуальная информация. При запросе о текущих событиях модель автоматически выполняет поиск и включает свежие данные в ответ. Результаты поиска обрабатываются с учётом контекста беседы, поэтому ответы получаются связными и релевантными.
Режим мышления (thinking mode)
Режим мышления появился в Gemini 2.5 Flash и меняет подход модели к сложным задачам. Вместо прямого ответа Flash сначала формулирует план решения, разбивает задачу на шаги и показывает процесс рассуждений. Вы видите, как модель пришла к выводу — это повышает доверие к результатам и помогает находить ошибки в логике.
В режиме мышления Flash тратит больше токенов на внутренние рассуждения, что увеличивает стоимость запроса. Google ввела параметр «бюджет мышления» — вы контролируете, сколько ресурсов модель может потратить на обдумывание. Это позволяет балансировать между качеством и ценой. Для простых задач бюджет можно снизить, для сложных — увеличить.
Режим мышления особенно полезен для программирования и математики. Flash разбирает задачу, рассматривает несколько подходов к решению и выбирает оптимальный. Модель объясняет, почему один алгоритм лучше другого, и предупреждает о потенциальных проблемах. Это помогает разработчикам понять решение, а не просто копировать код.
Стоимость режима мышления отличается от обычного режима. Без мышления выходные токены Gemini 2.5 Flash стоят $0,60 за миллион, с мышлением — $2,50 за миллион. Входные токены остаются по $0,30 за миллион. Для Flash-Lite цены ниже — $0,40 без мышления и $0,80 с мышлением за миллион выходных токенов. Включайте режим мышления только для задач, где он действительно улучшает результат.
Технические характеристики
Скорость работы
Gemini Flash обрабатывает запросы со скоростью более 250 токенов в секунду — это один из самых высоких показателей среди современных моделей. Для сравнения, GPT-4o выдаёт около 130 токенов в секунду, Claude 3 Sonnet — примерно 170. Высокая скорость делает Flash подходящим выбором для приложений реального времени — чат-ботов, голосовых ассистентов, интерактивных систем.
Время до первого токена (time-to-first-token) у Flash составляет около 0,25 секунды. Это задержка между отправкой запроса и получением начала ответа. Низкая задержка важна для разговорных интерфейсов — пользователи не ждут, диалог течёт естественно. Flash-Lite работает ещё быстрее за счёт упрощённой архитектуры.
Скорость зависит от типа задачи и размера контекста. Короткие запросы обрабатываются практически мгновенно, длинные документы требуют больше времени на загрузку и анализ. Мультимодальные запросы с видео работают медленнее текстовых, но всё равно быстрее, чем у конкурентов. Flash оптимизирована для параллельной обработки — одна инстанция модели справляется с сотнями одновременных запросов.
Google использует глобальную инфраструктуру для снижения задержек. Запросы обрабатываются в ближайшем дата-центре, что уменьшает время на передачу данных. Из Азиатско-Тихоокеанского региона задержка может вырасти до 4,5 секунды из-за маршрутизации через американские дата-центры. Для критичных по задержке приложений стоит учитывать географию пользователей.
Качество ответов (бенчмарки)
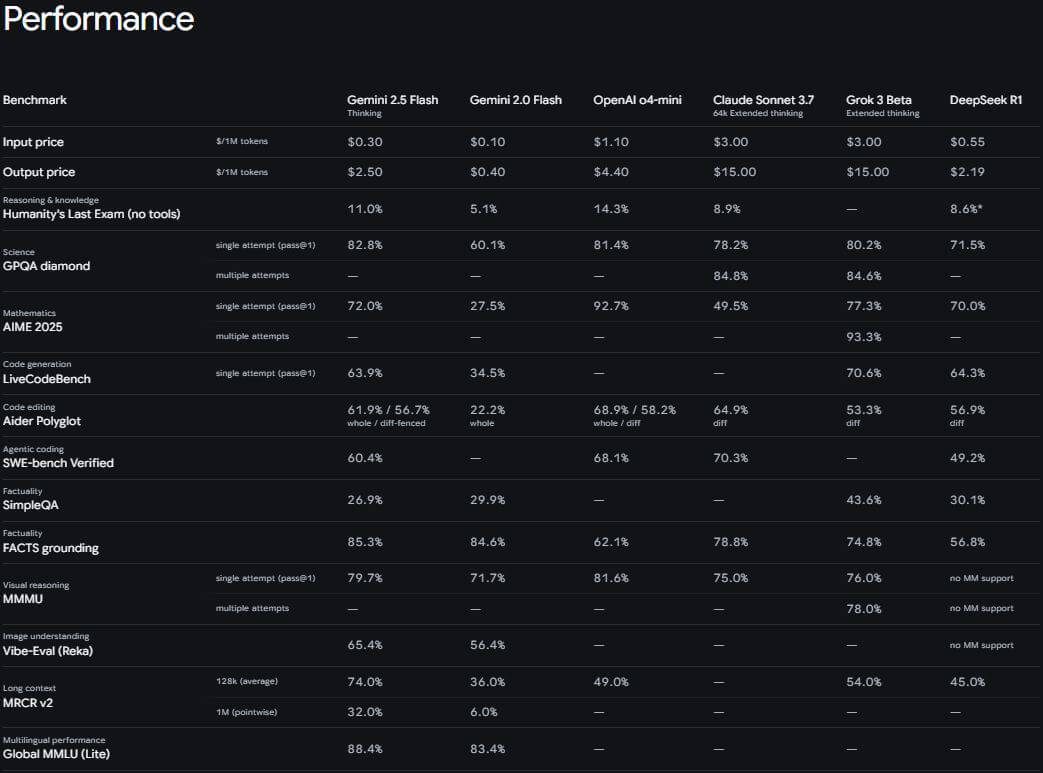
Gemini 2.5 Flash показывает результаты на уровне более дорогих моделей в большинстве бенчмарков. На MMLU (Massive Multitask Language Understanding) — тесте общих знаний — Flash набирает около 83—85%. Это сопоставимо с GPT-4o и немного уступает Claude 3.7 Sonnet с показателем 85%. Flash справляется с задачами по праву, медицине, философии и математике на экспертном уровне.
В программировании Flash демонстрирует сильные результаты. На HumanEval — тесте генерации кода — модель решает более 85% задач. На SWE-bench Verified, который проверяет способность исправлять баги в реальных проектах, Gemini 2.5 Flash достигает 54%. Это на 5% выше предыдущей версии и близко к результатам Gemini 2.5 Pro (63,8%). Claude 4 Sonnet лидирует с 72,7%, но стоит значительно дороже.
Математические способности Flash подтверждены на AIME 2024 — тесте для старшеклассников с высоким уровнем подготовки. Модель решает задачи с точностью около 70—75% в стандартном режиме. С включённым режимом мышления результаты улучшаются, хотя и не достигают показателей Claude Opus 4 с его 90% в режиме расширенного мышления.
На GPQA Diamond — тесте по научным дисциплинам уровня аспирантуры — все три лидирующие модели (Flash, GPT-4o, Claude) показывают близкие результаты в районе 83—84%. Это говорит о схожих способностях в глубоком анализе и рассуждениях. Flash уступает конкурентам в творческих задачах — написании текстов, генерации идей, стилистическом разнообразии. Здесь сильнее Claude и GPT-4o.
Поддержка языков
Gemini Flash работает с более чем 100 языками для ввода и вывода текста. Модель понимает запросы на русском, английском, китайском, испанском, арабском и десятках других языков. Google расширила языковую поддержку в версии 1.5, устранив блокировки по языку — теперь модель отвечает на любом из поддерживаемых языков без ограничений.
Качество работы варьируется в зависимости от языка. Английский показывает лучшие результаты — на нём обучалась большая часть данных. Русский, китайский и основные европейские языки работают хорошо для большинства задач. Для языков с меньшим объёмом обучающих данных точность может снижаться, особенно в специализированных темах.
Flash поддерживает перевод между всеми языками в своей базе. Модель сохраняет контекст при переводе — учитывает технические термины, культурные особенности и стиль исходного текста. Для многоязычных приложений это упрощает локализацию — один запрос переводит контент сразу на несколько языков с адаптацией под аудиторию.
Голосовые возможности доступны для 24 языков с одним и тем же голосом. Модель переключается между языками плавно, сохраняя естественность произношения. Вы управляете акцентом, тоном и эмоциональной окраской через текстовые команды — Flash адаптирует речь под контекст диалога. Это полезно для международных сервисов и образовательных приложений.
Ограничения модели
Gemini Flash иногда выдаёт галлюцинации — генерирует правдоподобно звучащую, но неверную информацию. Это общая проблема всех языковых моделей. По данным тестов, Flash показывает один из самых низких уровней галлюцинаций среди конкурентов, но риск остаётся. Для критичных применений нужна проверка фактов через внешние источники.
Модель ограничена датой обучения — основные знания Flash актуальны до января 2025 года. Для более свежей информации модель использует встроенный поиск Google, но это требует дополнительных вызовов инструментов. Без доступа к поиску Flash может давать устаревшие данные о текущих событиях, ценах, статистике.
Flash уступает флагманским моделям в глубине рассуждений. Для очень сложных задач — многошаговых математических доказательств, архитектурного проектирования систем, философского анализа — лучше подходит Gemini Pro или конкуренты вроде Claude 4 Opus с режимом расширенного мышления. Flash оптимизирована для скорости, а не максимальной точности в сложных кейсах.
Творческие способности Flash ниже, чем у GPT-4o и Claude. Модель справляется с техническими текстами, документацией и анализом, но в художественном письме, придумывании оригинальных концепций и стилистическом разнообразии проигрывает. Если задача требует креативности — создание рекламных слоганов, сценариев, литературных текстов — стоит рассмотреть альтернативы.
Стоимость использования
Цены через API
Gemini 2.5 Flash стоит $0,30 за миллион входных токенов и $2,50 за миллион выходных токенов с включённым режимом мышления. Это единая цена — Google убрала разделение на короткий и длинный контекст, которое было в версии 1.5. Теперь вы платите одинаково независимо от объёма загруженных данных. Без режима мышления цена на выход остаётся $0,60 за миллион токенов.
Для расчёта стоимости учитывайте, что примерно 4 символа равны одному токену. Текст из 1000 слов — это около 1300 токенов. Изображение размером 1024×1024 пикселя потребляет 1290 токенов. Видео расходует 258 токенов на секунду при частоте один кадр в секунду. Аудио обрабатывается с учётом длительности и качества записи.
Flash-Lite предлагает более выгодные цены — $0,10 за миллион входных токенов и $0,40 за выходные токены без мышления. С включённым режимом мышления выходные токены стоят $0,80 за миллион. Для высоконагруженных приложений разница существенна. Приложение, генерирующее 1000 изображений в день, потратит $1170 в месяц на стандартной Flash или $351 на Flash-Lite.
Для корпоративных клиентов через Vertex AI доступны индивидуальные тарифы. Google предлагает скидки на пакетную обработку — до 50% при использовании batch API. Кеширование промптов даёт дополнительную экономию до 75% на повторяющихся запросах. Если ваше приложение обрабатывает схожие данные, кеширование снижает расходы в разы.
Бесплатный доступ
Google AI Studio предоставляет бесплатный доступ к Gemini Flash без ограничений по функциям. Вы получаете 1500 запросов в день, 15 запросов в минуту и 1 млн токенов в минуту. Этого достаточно для разработки, тестирования и небольших проектов. Лимиты обновляются ежедневно в полночь по тихоокеанскому времени.
Бесплатный уровень включает все возможности платной версии — мультимодальность, большое контекстное окно, инструменты и функции. Ограничения касаются только скорости и объёма запросов. Для MVP или учебных проектов бесплатного тарифа хватит надолго. Google не требует банковскую карту для начала работы.
Во время пиковой нагрузки бесплатный уровень может работать медленнее из-за динамического троттлинга. Google распределяет ресурсы приоритетно для платных клиентов. На практике это означает задержки в несколько секунд при высокой загрузке серверов. Для продуктового использования лучше перейти на платный план с гарантированными лимитами.
Gemini доступен и через интерфейс Gemini Advanced за $19,99 в месяц. Этот план даёт приоритетный доступ к моделям, интеграцию с Gmail, Google Docs и другими сервисами Google. Для разработчиков API остаётся основным способом работы — он гибче и дешевле при больших объёмах запросов.
Оптимизация расходов
Кеширование промптов снижает расходы на повторяющиеся запросы. Если ваше приложение обрабатывает документы с одинаковой структурой, загрузите шаблон в кеш. Последующие запросы используют закешированный контекст и тратят токены только на уникальную часть. Google даёт скидку до 75% на закешированные входные токены.
Пакетная обработка через batch API экономит до 50% на больших объёмах. Вы отправляете массив запросов одновременно, Google обрабатывает их с меньшим приоритетом и снижает цену. Подходит для задач без жёстких требований к задержке — ночной анализ данных, формирование отчётов, предобучение систем.
Выбор правильной версии модели критичен для бюджета. Используйте Flash-Lite для простых задач, базовую Flash для сбалансированных кейсов и Pro только для сложной аналитики. Тестируйте задачи на разных моделях — часто Flash-Lite даёт достаточное качество при значительно меньшей стоимости. Многие компании переоценивают необходимость дорогих моделей.
Сокращайте промпты до минимума необходимой информации. Каждый лишний токен на входе увеличивает расходы. Структурируйте запросы чётко, избегайте повторов, используйте функции вместо длинных текстовых инструкций. Хорошо спроектированный промпт сокращает затраты в 2—3 раза без потери качества результата.
Главное о Gemini Flash
Gemini Flash — мощная мультимодальная модель, которая сочетает высокую производительность с доступной ценой. Модель обрабатывает текст, изображения, аудио и видео с контекстным окном в 1 млн токенов. Скорость работы превышает 250 токенов в секунду — вдвое быстрее основных конкурентов. Это делает Flash оптимальным выбором для продуктовых команд, стартапов и компаний с ограниченным бюджетом на ИИ.
Начните работу с бесплатного доступа в Google AI Studio — вы получаете 1500 запросов в день без ограничений по функциям. Этого достаточно для разработки прототипа и тестирования идей. При переходе в продакшен используйте Gemini API с гибким биллингом — платите только за использованные токены. Для корпоративных проектов Vertex AI предоставляет дополнительные гарантии безопасности, соответствия стандартам и масштабирования.