


DALL-E 2 — это система искусственного интеллекта, разработанная компанией OpenAI, которая создает оригинальные изображения и произведения искусства на основе текстового описания. Модель генерирует реалистичные картинки, комбинируя концепции, атрибуты и стили, руководствуясь пользовательским запросом. В условиях растущей потребности в визуальном контенте нейросеть предоставляет инструмент для творчества, дизайна и визуализации идей.
Что такое DALL-E 2
ИИ-модель была представлен OpenAI как развитие оригинальной модели DALL-E. Система сохранила базовые принципы работы, но получила улучшения в качестве генерации и понимании сложных запросов.
Основные характеристики
Это генеративная модель на основе архитектуры трансформеров. Обучение проводилось на наборе данных, содержащем изображения и текстовые описания. Для генерации изображений применяется диффузионная модель — процесс, который начинается с шума и постепенно преобразует его в целостное изображение, соответствующее текстовому запросу.
Особенности и возможности
Нейросеть представляет три основные функции:
- Создание изображений. Система генерирует изображения на основе текстовых описаний различной сложности.
- Редактирование существующих изображений. Модель позволяет вносить правки в загруженные изображения, добавляя или изменяя элементы с учетом контекста.
- Создание вариаций. На основе исходного изображения система может генерировать его вариации, сохраняя стиль и композицию.
Модель используется в различных областях:
- Маркетинг и реклама: создание визуального контента для рекламных кампаний и социальных сетей.
- Дизайн: генерация идей для дизайна продуктов и концепт-артов.
- Образование: создание иллюстраций для учебных материалов.
- Личное творчество: визуализация творческих идей без необходимости профессиональных художественных навыков.
ИИ-модель представляет собой инструмент, соединяющий текстовые описания с визуальным контентом, и продолжает использоваться для решения различных творческих и профессиональных задач.
Чтобы быть в курсе всех последних новостей и обзоров ИИ-технологий, а также использовать мощные ИИ-модели для своих проектов, переходите на платформу FICHI.AI.
Примеры использования
Кейс 1: маркетинг и реклама
Задача: создание визуального контента для продвижения экологичной косметики в социальных сетях.
Промпт: «Рекламный баннер для натурального шампуня: флакон из матового стекла на фоне свежих листьев алоэ и цветов ромашки, пастельные тона, естественное освещение, минималистичный стиль, место для текста слева».
Результат: модель сгенерировал вариант баннера с точной передачей текстур и цветовой гаммы. Изображение соответствует концепции бренда и готов к использованию в цифровой рекламе.
Кейс 2: дизайн
Задача: создание интерьера современной кофейни в индустриальном стиле.
Промпт: «Интерьер кофейни в лофт-стиле: кирпичные стены, деревянные столы из слэбов, подвесные Edison лампы, открытые вентиляционные трубы, зелень в горшках, панорамные окна с видом на город».
Результат: нейросеть сгенерировала вариант планировки помещения с детальной проработкой материалов и освещения.
Кейс 3: образование
Задача: создание иллюстрации для детской книги о динозаврах.
Промпт: «Милый детский рисунок: трицератопс с большими дружелюбными глазами играет в доисторическом лесу, яркие цвета, мультяшный стиль, подходит для книги дошкольников».
Результат: нейросеть создала красочное изображение динозавра. Иллюстрация была использована в детской книге без дополнительной обработки, значительно ускорив процесс подготовки издания.
Кейс 4: личное творчество
Задача: создание авторского граффити на основе слова «Freedom» (Свобода) для персонального творческого проекта.
Промпт: «Граффити слово "Freedom" в уличном стиле: объемные буквы с неоновой подсветкой, фон из кирпичной стены с брызгами краски, фиолетовые и синие оттенки, динамичная композиция».
Результат: было сгенерировано уникальное изображение граффити, трансформирующее слово в художественную композицию. Готовый результат передал задуманную энергию и цветовую гамму, и был использован в качестве основы для цифрового арт-объекта.
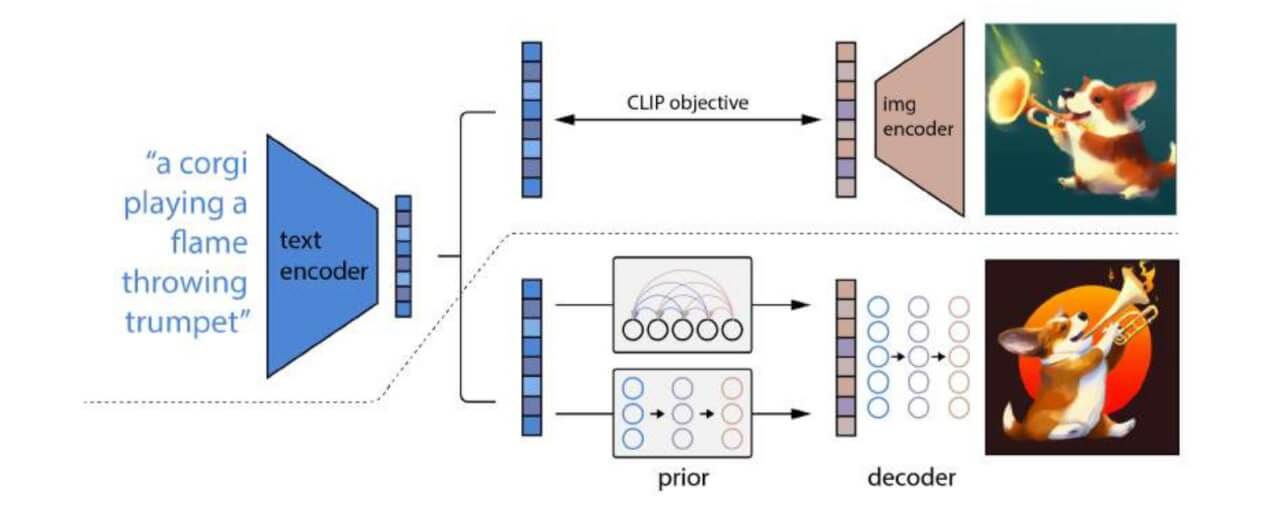
Анализ архитектуры DALL-E 2: как это работает
1. Текстовая обработка: от слов к идее
Первым делом текстовый промпт обрабатывается текстовым энкодером. В нейросети для этого используется модель CLIP, которая обучалась на миллионах пар «изображение-текст». Ее задача — преобразовать описание в семантический вектор, то есть в сжатое числовое представление его смысла. Этот вектор захватывает не просто отдельные слова, а связи между ними — например, то, что «огнеметная труба» это один объект, а не два разных.
2. Создание визуальной концепции: роль Приора (Prior)
Следующий и ключевой этап — работа Приора (Prior). Этот модуль выступает в роли «моста» между языком и изображением. Он берет семантический вектор от текстового энкодера и генерирует на его основе соответствующий визуальный вектор. Если текстовый энкодер создал «идею» изображения, то Приор превращает эту идею в конкретный «визуальный план», который понятен следующему модулю. Именно на этом этапе абстрактное описание «корги, играющий на огнеметной трубе» впервые обретает визуальные черты.
3. Визуализация: декодер создает пиксели
Финальный этап — работа Декодера. Этот модуль, часто называемый GLIDE или диффузионной моделью, получает от Приора визуальный вектор и преобразует его в настоящее изображение, pixel by pixel. Декодер итеративно уточняет картинку, начиная с шума, и постепенно «проявляет» в ней все детали, следуя полученному «плану». В результате мы получаем финальное изображение корги с трубой, из которой вырывается пламя.
Главная инновация DALL-E 2 заключается не в изобретении нового типа нейросети, а в гениальной комбинации уже существующих моделей (CLIP, диффузионная модель) через дополнительный модуль — Приор. Это позволяет системе сначала глубоко понять смысл запроса, а затем максимально точно и креативно его визуализировать, обеспечивая то самое высокое качество и соответствие тексту, которое поразило мир.
Плюсы и минусы
Сильные стороны
DALL-E 2 демонстрирует способность к семантическому синтезу различных концепций и визуальных стилей. Модель успешно интерпретирует сложные многосоставные запросы, создавая семантически согласованные изображения. Это обеспечивается обучением на обширном наборе данных, содержащем разнообразные изображения с текстовыми описаниями.
Архитектура диффузионной модели позволяет генерировать изображения с высоким разрешением, превосходящим возможности предыдущих версий системы. Модель демонстрирует способность к пространственному позиционированию объектов в соответствии с текстовым описанием композиции.
Ограничения и проблемы
Модель проявляет ограничения при работе с текстовыми элементами внутри изображений. Сгенерированные надписи часто содержат семантические и орфографические ошибки, что свидетельствует о недостаточном понимании лингвистических конструкций.
При визуализации антропоморфных объектов система может создавать артефакты в виде анатомических неточностей. Это проявляется в нарушении пропорций и естественных поз, что связано с архитектурными особенностями диффузионных моделей.
Система включает строгие фильтры контента, ограничивающие генерацию изображений по определенным тематикам. Однако механизмы модерации демонстрируют случаи избыточного срабатывания, блокируя этически нейтральные запросы.
Модель также показывает ограниченное понимание исторических и культурных контекстов, что может приводить к смешению стилистических элементов разных эпох при генерации тематических изображений.
Сравнительный анализ моделей генерации изображений OpenAI
| Критерий | DALL-E 2 | DALL-E 3 | GPT Image 1 Mini | GPT Image 1 |
| Тип модели | Специализированная генерация изображений | Улучшенная композиция и детализация | Экономная версия GPT Image 1 | Мультимодальная модель |
| Разрешение | 1024×1024, 1024×1536, 1536×1024 | 1024×1024, 1024×1536, 1536×1024 | 1024×1024, 1024×1536, 1536×1024 | 1024×1024, 1024×1536, 1536×1024 |
| Стоимость (стандартное качество) | $0.016-0.02 за изображение | $0.04-0.08 за изображение | $0.011-0.015 за изображение | $0.042-0.063 за изображение |
| Входные данные | Текст | Текст | Текст и изображения | Текст и изображения |
| Скорость | Медленная | Медленная | Очень медленная | Очень медленная |
| Особенности | Более гибкий промптинг | Высокое качество и детализация | Экономная версия | Нативная мультимодальность |
Ключевые выводы для пользователей:
- DALL-E 2 — оптимальный выбор для классической генерации изображений по текстовым описаниям. Модель предлагает баланс между качеством и стоимостью, поддерживая различные разрешения по доступной цене ($0.016-0.02 за изображение).
- DALL-E 3 — решение для задач, требующих повышенного качества и детализации. При стоимости $0.04-0.08 за изображение модель обеспечивает улучшенную композицию и проработку элементов, что делает её подходящей для профессиональных проектов.
- GPT Image 1 Mini — бюджетная альтернатива для тестирования и экспериментов. При самой низкой стоимости ($0.011-0.015) модель демонстрирует производительность выше средней, но работает медленнее аналогов.
- GPT Image 1 — флагманское решение для профессиональных задач. Модель устанавливает новые стандарты качества, поддерживая нативную мультимодальность (работа с текстом и изображениями), но требует значительных инвестиций ($0.042-0.063 за изображение).
Рекомендации по выбору:
- Для личного использования и экспериментов: DALL-E 2
- Для проектов с повышенными требованиями к качеству: DALL-E 3
- Для ограниченного бюджета: GPT Image 1 Mini
- Для коммерческих проектов и максимального качества: GPT Image 1
Каждая модель занимает свою нишу в экосистеме OpenAI, позволяя пользователям выбрать решение, соответствующее их задачам и бюджету.
DALL-E 2 доступен на платформе FICHI.AI
Модель интегрирована в экосистему FICHI.AI — сервиса, предоставляющего доступ к различным современным ИИ-инструментам. Это решение позволяет использовать возможности нейросети вместе с другими популярными моделями искусственного интеллекта в рамках единой платформы.
Ключевые преимущества использования через FICHI.AI:
- Упрощенный доступ без необходимости самостоятельной настройки API
- Возможность комбинировать генерацию изображений с другими ИИ-инструментами
- Удобный интерфейс для управления всеми нейросетевыми моделями
- Единая система работы с различными типами ИИ-решений
Интеграция с FICHI.AI делает работу с нейросетью более доступной для пользователей, которые хотят сосредоточиться на творческих задачах, а не на технической реализации.